컨볼루션 신경망 모델 만들어보기
간단한 컨볼루션 신경망 모델을 만들어봅니다. 다음과 같은 순서로 진행하겠습니다.
- 문제 정의하기
- 데이터 준비하기
- 데이터셋 생성하기
- 모델 구성하기
- 모델 학습과정 설정하기
- 모델 학습시키기
- 모델 평가하기
문제 정의하기
좋은 예제와 그와 관련된 데이터셋도 공개된 것이 많이 있지만, 직접 문제를 정의하고 데이터를 만들어보는 것도 처럼 딥러닝을 접하시는 분들에게는 크게 도움이 될 것 같습니다. 컨볼루션 신경망 모델에 적합한 문제는 이미지 기반의 분류입니다. 따라서 우리는 직접 손으로 삼각형, 사각형, 원을 그려 이미지로 저장한 다음 이를 분류해보는 모델을 만들어보겠습니다. 문제 형태와 입출력을 다음과 같이 정의해봅니다.
- 문제 형태 : 다중 클래스 분류
- 입력 : 손으로 그린 삼각형, 사각형, 원 이미지
- 출력 : 삼각형, 사각형, 원일 확률을 나타내는 벡터
가장 처음 필요한 패키지를 불러오고, 매번 실행 시마다 결과가 달라지지 않도록 랜덤 시드를 명시적으로 지정합니다.
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.preprocessing.image import ImageDataGenerator
# 랜덤시드 고정시키기
np.random.seed(3)
Using Theano backend.
데이터 준비하기
손으로 그린 삼각형, 사각형, 원 이미지를 만들기 위해서는 여러가지 방법이 있을 수 있겠네요. 테블릿을 이용할 수도 있고, 종이에 그려서 사진으로 찍을 수도 있습니다. 저는 그림 그리는 툴을 이용해서 만들어봤습니다. 이미지 사이즈는 24 x 24 정도로 해봤습니다.
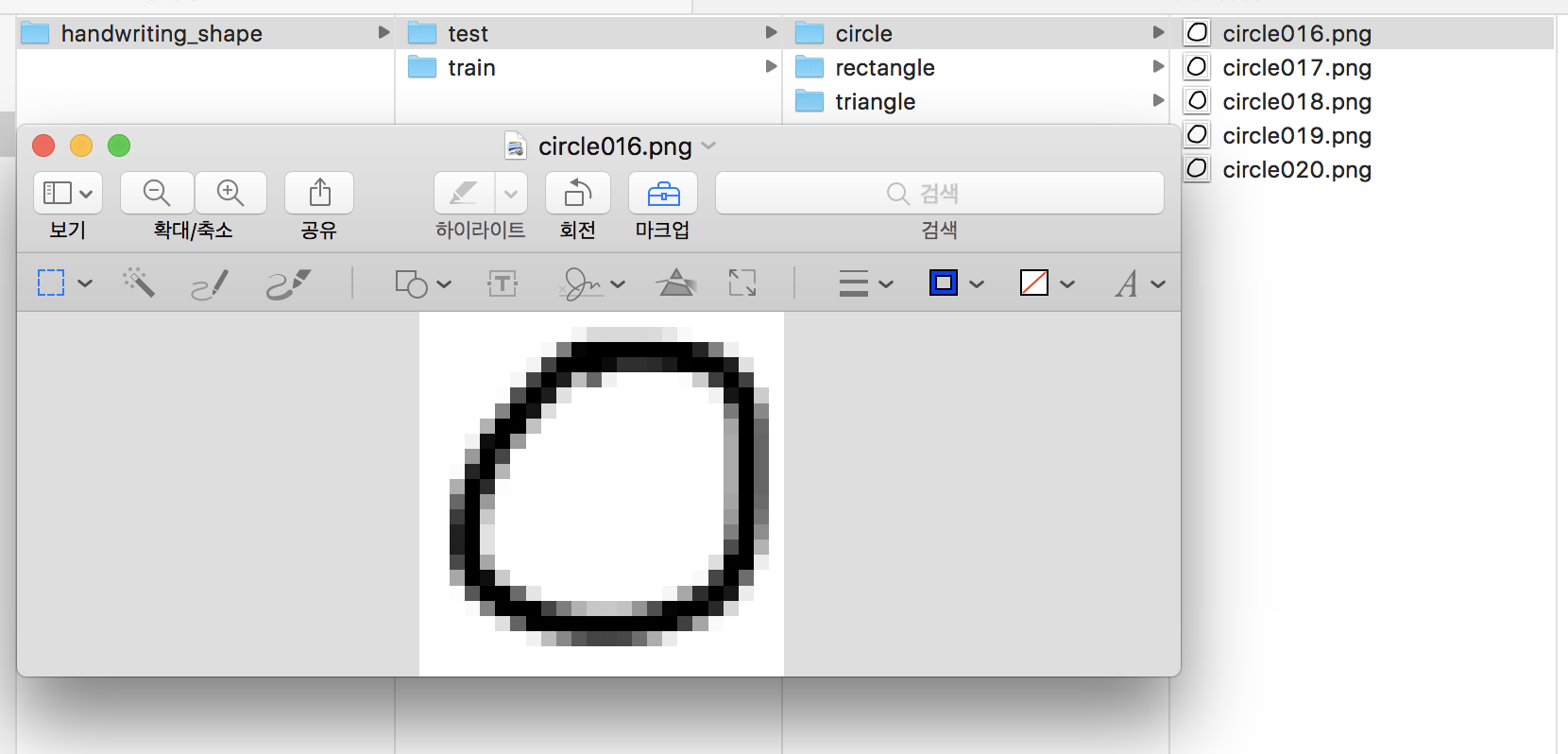
모양별로 20개 정도를 만들어서 15개를 훈련에 사용하고, 5개를 테스트에 사용해보겠습니다. 이미지는 png나 jpg로 저장합니다. 실제로 데이터셋이 어떻게 구성되어 있는 지 모른 체 튜토리얼을 따라하거나 예제 코드를 실행시키다보면 결과는 잘 나오지만 막상 실제 문제에 적용할 때 막막해질 때가 있습니다. 간단한 예제로 직접 데이터셋을 만들어봄으로써 실제 문제에 접근할 때 시행착오를 줄이는 것이 중요합니다.
데이터 폴더는 다음과 같이 구성했습니다.
- train
- circle
- rectangle
- triangle
- test
- circle
- rectangle
- triangle
직접 그려보시는 것을 권장하시만 아래 링크에서 다운로드를 받으실 수 있습니다.
http://tykimos.github.io/warehouse/2017-3-8_CNN_Getting_Started_handwriting_shape.zip
데이터셋 생성하기
케라스에서는 이미지 파일을 쉽게 학습시킬 수 있도록 ImageDataGenerator 클래스를 제공합니다. ImageDataGenerator 클래스는 데이터 증강 (data augmentation)을 위해 막강한 기능을 제공하는 데, 이 기능들은 다른 강좌에세 다루기로 하고, 본 강좌에서는 특정 폴더에 이미지를 분류 해놓았을 때 이를 학습시키기 위한 데이터셋으로 만들어주는 기능을 사용해보겠습니다.
먼저 ImageDataGenerator 클래스를 이용하여 객체를 생성한 뒤 flow_from_directory() 함수를 호출하여 제네레이터(generator)를 생성합니다. flow_from_directory() 함수의 주요인자는 다음과 같습니다.
- 첫번재 인자 : 이미지 경로를 지정합니다.
- target_size : 패치 이미지 크기를 지정합니다. 폴더에 있는 원본 이미지 크기가 다르더라도 target_size에 지정된 크기로 자동 조절됩니다.
- batch_size : 배치 크기를 지정합니다.
- class_mode : 분류 방식에 대해서 지정합니다.
- categorical : 2D one-hot 부호화된 라벨이 반환됩니다.
- binary : 1D 이진 라벨이 반환됩니다.
- sparse : 1D 정수 라벨이 반환됩니다.
- None : 라벨이 반환되지 않습니다.
본 예제에서는 패치 이미지 크기를 24 x 24로 하였으니 target_size도 (24, 24)로 셋팅하였습니다. 훈련 데이터 수가 클래스당 15개이니 배치 크기를 3으로 지정하여 총 5번 배치를 수행하면 하나의 epoch가 수행될 수 있도록 하였습니다. 다중 클래스 문제이므로 class_mode는 ‘categorical’로 지정하였습니다. 그리고 제네레이터는 훈련용과 검증용으로 두 개를 만들었습니다.
train_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
'warehouse/handwriting_shape/train',
target_size=(24, 24),
batch_size=3,
class_mode='categorical')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
'warehouse/handwriting_shape/test',
target_size=(24, 24),
batch_size=3,
class_mode='categorical')
Found 45 images belonging to 3 classes.
Found 15 images belonging to 3 classes.
모델 구성하기
영상 분류에 높은 성능을 보이고 있는 컨볼루션 신경망 모델을 구성해보겠습니다. 각 레이어들은 이전 강좌에서 살펴보았으므로 크게 어려움없이 구성할 수 있습니다.
- 컨볼루션 레이어 : 입력 이미지 크기 24 x 24, 입력 이미지 채널 3개, 필터 크기 3 x 3, 필터 수 32개, 활성화 함수 ‘relu’
- 컨볼루션 레이어 : 필터 크기 3 x 3, 필터 수 64개, 활성화 함수 ‘relu’
- 맥스풀링 레이어 : 풀 크기 2 x 2
- 플래튼 레이어
- 댄스 레이어 : 출력 뉴런 수 128개, 활성화 함수 ‘relu’
- 댄스 레이어 : 출력 뉴런 수 3개, 활성화 함수 ‘softmax’
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=(24,24,3)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(3, activation='softmax'))
구성한 모델을 가시화하면 다음과 같습니다.
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
%matplotlib inline
SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg'))


모델 학습과정 설정하기
모델을 정의했다면 모델을 손실함수와 최적화 알고리즘으로 엮어봅니다.
- loss : 현재 가중치 세트를 평가하는 데 사용한 손실 함수 입니다. 다중 클래스 문제이므로 ‘categorical_crossentropy’으로 지정합니다.
- optimizer : 최적의 가중치를 검색하는 데 사용되는 최적화 알고리즘으로 효율적인 경사 하강법 알고리즘 중 하나인 ‘adam’을 사용합니다.
- metrics : 평가 척도를 나타내며 분류 문제에서는 일반적으로 ‘accuracy’으로 지정합니다.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
모델 학습시키기
케라스에서는 모델을 학습시킬 때 주로 fit() 함수를 사용하지만 제네레이터로 생성된 배치로 학습시킬 경우에는 fit_generator() 함수를 사용합니다. 본 예제에서는 ImageDataGenerator라는 제네레이터로 이미지를 담고 있는 배치로 학습시키기 때문에 fit_generator() 함수를 사용하겠습니다.
- 첫번째 인자 : 훈련데이터셋을 제공할 제네레이터를 지정합니다. 본 예제에서는 앞서 생성한 train_generator으로 지정합니다.
- steps_per_epoch : 한 epoch에 사용한 스텝 수를 지정합니다. 총 45개의 훈련 샘플이 있고 배치사이즈가 3이므로 15 스텝으로 지정합니다.
- epochs : 전체 훈련 데이터셋에 대해 학습 반복 횟수를 지정합니다. 100번을 반복적으로 학습시켜 보겠습니다.
- validation_data : 검증데이터셋을 제공할 제네레이터를 지정합니다. 본 예제에서는 앞서 생성한 validation_generator으로 지정합니다.
- validation_steps : 한 epoch 종료 시 마다 검증할 때 사용되는 검증 스텝 수를 지정합니다. 홍 15개의 검증 샘플이 있고 배치사이즈가 3이므로 5 스텝으로 지정합니다.
model.fit_generator(
train_generator,
steps_per_epoch=15,
epochs=50,
validation_data=test_generator,
validation_steps=5)
Epoch 1/50
15/15 [==============================] - 0s - loss: 0.8595 - acc: 0.5778 - val_loss: 0.5781 - val_acc: 1.0000
Epoch 2/50
15/15 [==============================] - 0s - loss: 0.1930 - acc: 0.9778 - val_loss: 0.1103 - val_acc: 1.0000
Epoch 3/50
15/15 [==============================] - 0s - loss: 0.0187 - acc: 1.0000 - val_loss: 0.2022 - val_acc: 0.9333
...
Epoch 48/50
15/15 [==============================] - 0s - loss: 8.8877e-07 - acc: 1.0000 - val_loss: 7.7623e-04 - val_acc: 1.0000
Epoch 49/50
15/15 [==============================] - 0s - loss: 7.3380e-07 - acc: 1.0000 - val_loss: 0.1564 - val_acc: 0.8667
Epoch 50/50
15/15 [==============================] - 0s - loss: 8.2784e-07 - acc: 1.0000 - val_loss: 0.0676 - val_acc: 1.0000
<keras.callbacks.History at 0x1102a3110>
모델 평가하기
학습한 모델을 평가해봅니다. 제네레이터에서 제공되는 샘플로 평가할 때는 evaluate_generator 함수를 사용합니다.
print("-- Evaluate --")
scores = model.evaluate_generator(test_generator, steps=5)
print("%s: %.2f%%" %(model.metrics_names[1], scores[1]*100))
-- Evaluate --
acc: 100.00%
데이터셋이 적고 간단한 모델임에도 불구하고 100%라는 높은 정확도를 얻었습니다.
모델 사용하기
모델 사용 시에 제네레이터에서 제공되는 샘플을 입력할 때는 predict_generator 함수를 사용합니다. 예측 결과는 클래스별 확률 벡터로 출력되며, 클래스에 해당하는 열을 알기 위해서는 제네레이터의 ‘class_indices’를 출력하면 해당 열의 클래스명을 알려줍니다.
print("-- Predict --")
output = model.predict_generator(test_generator, steps=5)
np.set_printoptions(formatter={'float': lambda x: "{0:0.3f}".format(x)})
print(test_generator.class_indices)
print(output)
-- Predict --
{'circle': 0, 'triangle': 2, 'rectangle': 1}
[[1.000 0.000 0.000]
[0.315 0.363 0.322]
[0.000 1.000 0.000]
[0.000 0.006 0.994]
[1.000 0.000 0.000]
[0.000 1.000 0.000]
[0.000 1.000 0.000]
[1.000 0.000 0.000]
[0.000 0.001 0.999]
[1.000 0.000 0.000]
[1.000 0.000 0.000]
[1.000 0.000 0.000]
[0.000 0.006 0.994]
[0.315 0.363 0.322]
[0.000 0.000 1.000]]
전체 소스
# 0. 사용할 패키지 불러오기
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.preprocessing.image import ImageDataGenerator
# 랜덤시드 고정시키기
np.random.seed(3)
# 1. 데이터 생성하기
train_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
'warehouse/handwriting_shape/train',
target_size=(24, 24),
batch_size=3,
class_mode='categorical')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
'warehouse/handwriting_shape/test',
target_size=(24, 24),
batch_size=3,
class_mode='categorical')
# 2. 모델 구성하기
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=(24,24,3)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(3, activation='softmax'))
# 3. 모델 학습과정 설정하기
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 4. 모델 학습시키기
model.fit_generator(
train_generator,
steps_per_epoch=15,
epochs=50,
validation_data=test_generator,
validation_steps=5)
# 5. 모델 평가하기
print("-- Evaluate --")
scores = model.evaluate_generator(test_generator, steps=5)
print("%s: %.2f%%" %(model.metrics_names[1], scores[1]*100))
# 6. 모델 사용하기
print("-- Predict --")
output = model.predict_generator(test_generator, steps=5)
np.set_printoptions(formatter={'float': lambda x: "{0:0.3f}".format(x)})
print(test_generator.class_indices)
print(output)
Found 45 images belonging to 3 classes.
Found 15 images belonging to 3 classes.
Epoch 1/50
15/15 [==============================] - 0s - loss: 0.9365 - acc: 0.5778 - val_loss: 0.4891 - val_acc: 1.0000
Epoch 2/50
15/15 [==============================] - 0s - loss: 0.1786 - acc: 1.0000 - val_loss: 0.0679 - val_acc: 1.0000
Epoch 3/50
15/15 [==============================] - 0s - loss: 0.0233 - acc: 1.0000 - val_loss: 0.0777 - val_acc: 1.0000
...
Epoch 48/50
15/15 [==============================] - 0s - loss: 6.2121e-07 - acc: 1.0000 - val_loss: 0.0031 - val_acc: 1.0000
Epoch 49/50
15/15 [==============================] - 0s - loss: 6.0002e-07 - acc: 1.0000 - val_loss: 0.0033 - val_acc: 1.0000
Epoch 50/50
15/15 [==============================] - 0s - loss: 5.7883e-07 - acc: 1.0000 - val_loss: 0.0032 - val_acc: 1.0000
-- Evaluate --
acc: 100.00%
-- Predict --
{'circle': 0, 'triangle': 2, 'rectangle': 1}
[[0.000 0.000 1.000]
[0.000 1.000 0.000]
[0.000 0.000 1.000]
[0.000 1.000 0.000]
[0.000 0.000 1.000]
[1.000 0.000 0.000]
[0.016 0.956 0.028]
[0.000 1.000 0.000]
[0.000 0.000 1.000]
[0.998 0.000 0.002]
[0.000 0.000 1.000]
[0.016 0.956 0.028]
[0.000 0.000 1.000]
[0.000 1.000 0.000]
[1.000 0.000 0.000]]
요약
이미지 분류 문제에 높은 성능을 보이고 있는 컨볼루션 신경망 모델을 이용하여 직접 만든 데이터셋으로 학습 및 평가를 해보았습니다. 학습 결과는 좋게 나왔지만 이 모델은 한 사람이 그린 것에 대해서만 학습이 되어 있어 다른 사람에 그린 모양은 분류를 잘 하지 못합니다. 이를 해결하기 위한 방안으로 ‘데이터 부풀리기’ 기법이 있습니다.
참고로 실제 문제에 적용하기 전에 데이터셋을 직접 만들어보거나 좀 더 쉬운 문제로 추상화해서 프로토타이핑 하시는 것을 권장드립니다. 객담도말된 결핵 이미지 판별하는 모델을 만들 때, 결핵 이미지를 바로 사용하지 않고, MNIST의 손글씨 중 ‘1’과 ‘7’을 결핵이라고 보고, 나머지는 결핵이 아닌 것으로 학습시켜봤었습니다. 결핵균이 간균 (막대모양)이라 적절한 프로토타이핑이었고, 프로토타이핑 모델과 실제 데이터셋으로 학습한 모델 결과가 크게 차이나지 않았습니다.
같이 보기
- 강좌 목차
- 이전 : 컨볼루션 신경망 레이어 이야기
- 다음 : 컨볼루션 신경망 모델을 위한 데이터 부풀리기
책 소개

[추천사]
- 하용호님, 카카오 데이터사이언티스트 - 뜬구름같은 딥러닝 이론을 블록이라는 손에 잡히는 실체로 만져가며 알 수 있게 하고, 구현의 어려움은 케라스라는 시를 읽듯이 읽어내려 갈 수 있는 라이브러리로 풀어준다.
- 이부일님, (주)인사아트마이닝 대표 - 여행에서도 좋은 가이드가 있으면 여행지에 대한 깊은 이해로 여행이 풍성해지듯이 이 책은 딥러닝이라는 분야를 여행할 사람들에 가장 훌륭한 가이드가 되리라고 자부할 수 있다. 이 책을 통하여 딥러닝에 대해 보지 못했던 것들이 보이고, 듣지 못했던 것들이 들리고, 말하지 못했던 것들이 말해지는 경험을 하게 될 것이다.
- 이활석님, 네이버 클로바팀 - 레고 블럭에 비유하여 누구나 이해할 수 있게 쉽게 설명해 놓은 이 책은 딥러닝의 입문 도서로서 제 역할을 다 하리라 믿습니다.
- 김진중님, 야놀자 Head of STL - 복잡했던 머릿속이 맑고 깨끗해지는 효과가 있습니다.
- 이태영님, 신한은행 디지털 전략부 AI LAB - 기존의 텐서플로우를 활용했던 분들에게 바라볼 수 있는 관점의 전환점을 줄 수 있는 Mild Stone과 같은 책이다.
- 전태균님, 쎄트렉아이 - 케라스의 특징인 단순함, 확장성, 재사용성을 눈으로 쉽게 보여주기 위해 친절하게 정리된 내용이라 생각합니다.
- 유재준님, 카이스트 - 바로 적용해보고 싶지만 어디부터 시작할지 모를 때 최선의 선택입니다.