컨볼루션 신경망 모델을 위한 데이터 부풀리기
본 강좌에서는 컨볼루션 신경망 모델의 성능을 높이기 위한 방법 중 하나인 데이터 부풀리기에 대해서 알아보겠습니다. 훈련셋이 부족하거나 훈련셋이 시험셋의 특성을 충분히 반영하지 못할 때 이 방법을 사용하면 모델의 성능을 크게 향상시킬 수 있습니다. 케라스에서는 데이터 부풀리기를 위한 함수를 제공하기 때문에 파라미터 셋팅만으로 간단히 데이터 부풀리기를 할 수 있습니다.
- 현실적인 문제
- 기존 모델 결과보기
- 데이터 부풀리기
- 개선 모델 결과보기
현실적인 문제
컨볼루션 신경망 모델 만들어보기 강좌에서 사용하였던 원, 사각형, 삼각형 데이터셋을 예제로 살펴보겠습니다. 구성은 훈련셋과 시험셋으로 되어 있는 데, 아래 그림은 훈련셋입니다.
훈련셋

그리고 아래 그림은 시험셋입니다. 훈련셋과 시험셋은 모두 한사람(제가) 그린 것이라 거의 비슷합니다. 그래서 그런지 100% 정확도의 좋은 결과를 얻었나 봅니다.
시험셋

100% 정확도를 얻은 모델이니 원, 사각형, 삼각형을 그려주면 다 분류를 해보겠다며 지인에게 자랑을 해봅니다. 그래서 지인이 그려준 시험셋은 다음과 같습니다.
도전 시험셋

막상 시험셋을 받아보니 자신감이 없어지면서 여러가지 생각이 듭니다.
- 아, 이것도 원, 사각형, 삼각형이구나
- 왜 이런 데이터를 진작에 학습시키지 않았을까?
- 새로 받은 시험셋 일부를 학습시켜볼까?
- 이렇게 간단한 문제도 개발과 현실과의 차이가 이렇게 나는데, 실제 문제는 더 상황이 좋지 않겠지?
결국 하나의 결론에 도달합니다.
개발자가 시험셋을 만들면 안된다.
하지만 어떠한 문제에서도 미래에 들어올 데이터에 대해서는 알 수가 없기 때문에, 비슷한 상황일 것 같습니다. 먼저 도전 시험셋으로 시험한 결과를 살펴본 뒤, 한정적인 훈련셋을 이용하여 최대한 발생할 수 있는 경우을 고려하여 훈련셋을 만드는 방법인 데이터 부풀리기에 대해서 알아보겠습니다.
기존 모델 결과보기
컨볼루션 신경망 모델 만들어보기 강좌에서 사용했던 모델을 그대로 가지고 왔습니다. 제가 만든 시험셋에서는 결과가 100%나왔는데, 도전 시험셋으론 어떤 결과가 나오는 지 테스트해보겠습니다.
import numpy as np
# 랜덤시드 고정시키기
np.random.seed(3)
from keras.preprocessing.image import ImageDataGenerator
# 데이터셋 불러오기
train_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
'warehouse/hard_handwriting_shape/train',
target_size=(24, 24),
batch_size=3,
class_mode='categorical')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
'warehouse/hard_handwriting_shape/test',
target_size=(24, 24),
batch_size=3,
class_mode='categorical')
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
# 모델 구성하기
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=(24,24,3)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(3, activation='softmax'))
# 모델 엮기
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델 학습시키기
model.fit_generator(
train_generator,
steps_per_epoch=15,
epochs=200,
validation_data=test_generator,
validation_steps=5)
# 모델 평가하기
print("-- Evaluate --")
scores = model.evaluate_generator(
test_generator,
steps = 5)
print("%s: %.2f%%" %(model.metrics_names[1], scores[1]*100))
# 모델 예측하기
print("-- Predict --")
output = model.predict_generator(
test_generator,
steps = 5)
np.set_printoptions(formatter={'float': lambda x: "{0:0.3f}".format(x)})
print(output)
Found 45 images belonging to 3 classes.
Found 15 images belonging to 3 classes.
Epoch 1/200
15/15 [==============================] - 0s - loss: 0.9365 - acc: 0.5778 - val_loss: 1.7078 - val_acc: 0.3333
Epoch 2/200
15/15 [==============================] - 0s - loss: 0.1786 - acc: 1.0000 - val_loss: 2.8848 - val_acc: 0.4000
Epoch 3/200
15/15 [==============================] - 0s - loss: 0.0233 - acc: 1.0000 - val_loss: 4.3072 - val_acc: 0.4000
Epoch 4/200
15/15 [==============================] - 0s - loss: 0.0148 - acc: 1.0000 - val_loss: 4.3684 - val_acc: 0.4000
Epoch 5/200
15/15 [==============================] - 0s - loss: 0.0338 - acc: 0.9778 - val_loss: 4.7764 - val_acc: 0.4000
...
Epoch 196/200
15/15 [==============================] - 0s - loss: 1.2186e-07 - acc: 1.0000 - val_loss: 6.2569 - val_acc: 0.4667
Epoch 197/200
15/15 [==============================] - 0s - loss: 1.2186e-07 - acc: 1.0000 - val_loss: 7.4963 - val_acc: 0.4000
Epoch 198/200
15/15 [==============================] - 0s - loss: 1.2186e-07 - acc: 1.0000 - val_loss: 7.4959 - val_acc: 0.4000
Epoch 199/200
15/15 [==============================] - 0s - loss: 1.2186e-07 - acc: 1.0000 - val_loss: 7.4956 - val_acc: 0.4000
Epoch 200/200
15/15 [==============================] - 0s - loss: 1.2186e-07 - acc: 1.0000 - val_loss: 7.4950 - val_acc: 0.4000
-- Evaluate --
acc: 40.00%
-- Predict --
[[0.000 0.013 0.987]
[0.000 0.000 1.000]
[0.000 0.000 1.000]
[0.000 0.000 1.000]
[0.000 0.000 1.000]
[0.000 0.000 1.000]
[0.000 0.000 1.000]
[0.000 0.000 1.000]
[0.000 0.000 1.000]
[0.727 0.001 0.272]
[0.000 0.000 1.000]
[0.000 0.000 1.000]
[0.000 0.013 0.987]
[0.000 0.000 1.000]
[0.000 0.000 1.000]]
수행결과는 40%입니다. 세개 중 하나 찍는 문제인데도 불구하고 50%로 못 넘깁니다. 오버피팅이 제대로 된 모델이라고 볼 수 있습니다.
데이터 부풀리기
케라스에서는 ImageDataGenerator 함수를 통해서 데이터 부풀리기 기능을 제공합니다. keras.io 페이지를 보면, 아래와 같은 옵션으로 데이터 부풀리기를 할 수 있습니다.
keras.preprocessing.image.ImageDataGenerator(featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
rotation_range=0.,
width_shift_range=0.,
height_shift_range=0.,
shear_range=0.,
zoom_range=0.,
channel_shift_range=0.,
fill_mode='nearest',
cval=0.,
horizontal_flip=False,
vertical_flip=False,
rescale=None,
preprocessing_function=None,
data_format=K.image_data_format())
그럼 훈련셋 중 하나인 삼각형을 골라 데이터 부풀리기를 해보겠습니다. 원본이 되는 삼각형은 다음과 같습니다.

이 삼각형을 ImageDataGenerator 함수을 이용하여 각 파라미터별로 어떻게 부풀리기를 하는 지 살펴보겠습니다.
rotation_range = 90
지정된 각도 범위내에서 임의로 원본이미지를 회전시킵니다. 단위는 도이며, 정수형입니다. 예를 들어 90이라면 0도에서 90도 사이에 임의의 각도로 회전시킵니다.

width_shift_range = 0.1
지정된 수평방향 이동 범위내에서 임의로 원본이미지를 이동시킵니다. 수치는 전체 넓이의 비율(실수)로 나타냅니다. 예를 들어 0.1이고 전체 넓이가 100이면, 10픽셀 내외로 좌우 이동시킵니다.

height_shift_range = 0.1
지정된 수직방향 이동 범위내에서 임의로 원본이미지를 이동시킵니다. 수치는 전체 높이의 비율(실수)로 나타냅니다. 예를 들어 0.1이고 전체 높이가 100이면, 10픽셀 내외로 상하 이동시킵니다.

shear_range = 0.5
밀림 강도 범위내에서 임의로 원본이미지를 변형시킵니다. 수치는 시계반대방향으로 밀림 강도를 라디안으로 나타냅니다. 예를 들어 0.5이라면, 0.5 라이안내외로 시계반대방향으로 변형시킵니다.

zoom_range = 0.3
지정된 확대/축소 범위내에서 임의로 원본이미지를 확대/축소합니다. “1-수치”부터 “1+수치”사이 범위로 확대/축소를 합니다. 예를 들어 0.3이라면, 0.7배에서 1.3배 크기 변화를 시킵니다.

horizontal_flip = True
수평방향으로 뒤집기를 합니다.

vertical_flip = True
수직방향으로 뒤집기를 합니다.

아래 코드는 ImageDataGenerator함수를 이용하여 지정된 파라미터로 원본이미지에 대해 데이터 부풀리기를 수행한 후 그 결과를 특정 폴더에 저장하는 코드입니다. 여러 파라미터를 사용하였기 때문에 이를 혼합하여 데이터 부풀리기를 수행합니다. 즉 확대/축소도 하고 좌우 이동도 지정하였다면, 축소하면서 좌로 이동된 이미지도 생성됩니다.
import numpy as np
# 랜덤시드 고정시키기
np.random.seed(5)
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
# 데이터셋 불러오기
data_aug_gen = ImageDataGenerator(rescale=1./255,
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.5,
zoom_range=[0.8, 2.0],
horizontal_flip=True,
vertical_flip=True,
fill_mode='nearest')
img = load_img('warehouse/hard_handwriting_shape/train/triangle/triangle001.png')
x = img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
# 이 for는 무한으로 반복되기 때문에 우리가 원하는 반복횟수를 지정하여, 지정된 반복횟수가 되면 빠져나오도록 해야합니다.
for batch in train_datagen.flow(x, batch_size=1, save_to_dir='warehouse/preview', save_prefix='tri', save_format='png'):
i += 1
if i > 30:
break
위 코드로 데이터 부풀리기가 수행된 결과 이미지는 다음과 같습니다. 지인이 만든 도전 시험셋 중 비슷한 것들도 보입니다.
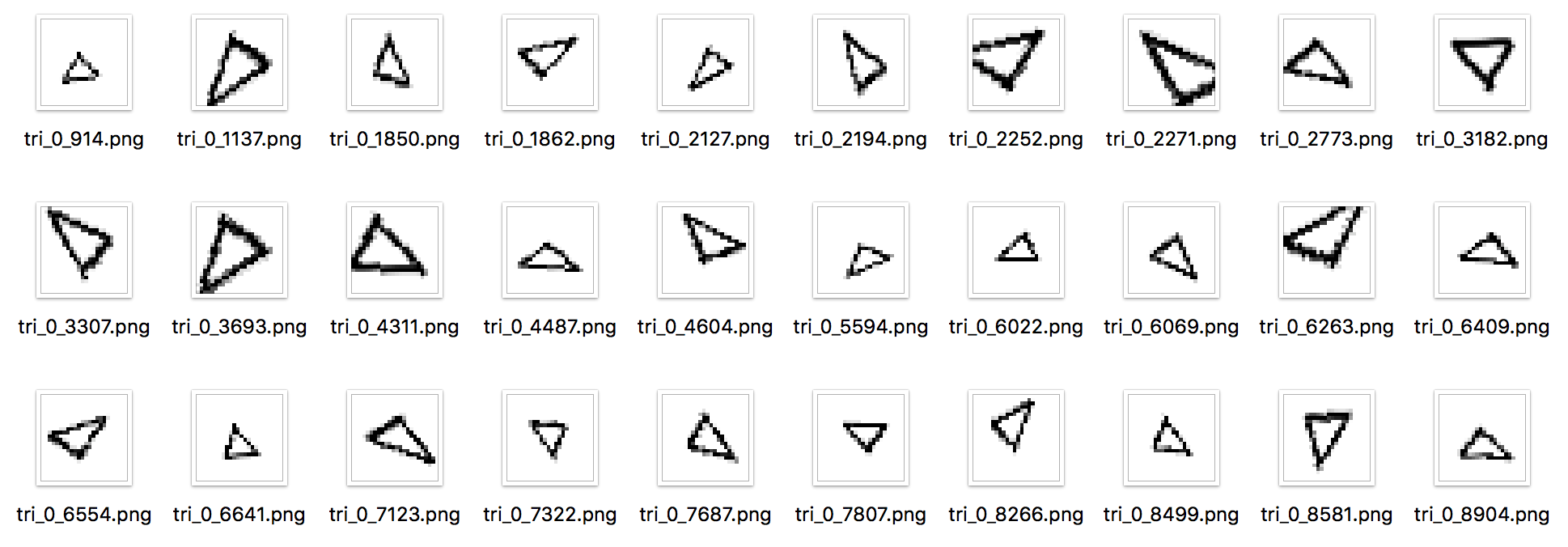
개선 모델 결과보기
데이터 부풀리기를 하기 위해서는 기존 코드에서 아래 코드를 추가합니다. 각 파라미터 설정 값에 따라 결과가 다르기 나오니, 실제 데이터에 있을만한 수준으로 적정값을 지정하셔야 합니다.
# 데이터셋 불러오기
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.5,
zoom_range=[0.8, 2.0],
horizontal_flip=True,
vertical_flip=True,
fill_mode='nearest')
수정된 전체 코드는 다음과 같습니다. 참고로 시험셋은 데이터 부풀리기를 할 필요가 없으니, test_datagen 객체 생성 시에는 별도의 파라미터를 추가하지 않았습니다. 그리고 fit_generator함수에서 steps_per_epoch의 값은 기존 15개에서 더 많은 수 (현재 예는 1500개)로 설정합니다. batch_size * steps_per_epoch가 전체 샘플 수 인데, 데이터 부풀리기를 하지 않을 때는 기존의 15개의 배치사이즈(3개)로 전체 45개를 모두 학습에 사용할 수 있지만, ImageDataGenerator함수를 통해 데이터 부풀리기는 할 때는 하나의 샘플로 여러 개의 결과를 얻기 때문에 요청하는 데로 무한의 샘플이 제공됩니다. 여기서는 100배 정도인 1500개로 설정했습니다.
import numpy as np
# 랜덤시드 고정시키기
np.random.seed(3)
from keras.preprocessing.image import ImageDataGenerator
# 데이터셋 불러오기
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=10,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.7,
zoom_range=[0.9, 2.2],
horizontal_flip=True,
vertical_flip=True,
fill_mode='nearest')
train_generator = train_datagen.flow_from_directory(
'warehouse/hard_handwriting_shape/train',
target_size=(24, 24),
batch_size=3,
class_mode='categorical')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
'warehouse/hard_handwriting_shape/test',
target_size=(24, 24),
batch_size=3,
class_mode='categorical')
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers import Dropout
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=(24,24,3)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(3, activation='softmax'))
# 모델 엮기
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델 학습시키기
model.fit_generator(
train_generator,
steps_per_epoch=15 * 100,
epochs=200,
validation_data=test_generator,
validation_steps=5)
# 모델 평가하기
print("-- Evaluate --")
scores = model.evaluate_generator(
test_generator,
steps = 5)
print("%s: %.2f%%" %(model.metrics_names[1], scores[1]*100))
# 모델 예측하기
print("-- Predict --")
output = model.predict_generator(
test_generator,
steps = 5)
np.set_printoptions(formatter={'float': lambda x: "{0:0.3f}".format(x)})
print(output)
Found 45 images belonging to 3 classes.
Found 15 images belonging to 3 classes.
Epoch 1/200
1500/1500 [==============================] - 31s - loss: 0.4396 - acc: 0.8109 - val_loss: 2.0550 - val_acc: 0.6000
Epoch 2/200
1500/1500 [==============================] - 41s - loss: 0.1653 - acc: 0.9427 - val_loss: 1.7761 - val_acc: 0.8000
Epoch 3/200
1500/1500 [==============================] - 42s - loss: 0.1155 - acc: 0.9609 - val_loss: 2.5279 - val_acc: 0.6000
Epoch 4/200
1500/1500 [==============================] - 43s - loss: 0.0958 - acc: 0.9689 - val_loss: 2.7588 - val_acc: 0.5333
Epoch 5/200
1500/1500 [==============================] - 44s - loss: 0.0624 - acc: 0.9789 - val_loss: 3.4055 - val_acc: 0.6000
...
Epoch 196/200
1500/1500 [==============================] - 99s - loss: 0.0698 - acc: 0.9942 - val_loss: 4.7934 - val_acc: 0.6667
Epoch 197/200
1500/1500 [==============================] - 100s - loss: 0.0517 - acc: 0.9951 - val_loss: 3.3569 - val_acc: 0.6667
Epoch 198/200
1500/1500 [==============================] - 101s - loss: 0.0371 - acc: 0.9958 - val_loss: 3.4091 - val_acc: 0.6667
Epoch 199/200
1500/1500 [==============================] - 101s - loss: 0.0611 - acc: 0.9949 - val_loss: 3.0024 - val_acc: 0.8000
Epoch 200/200
1500/1500 [==============================] - 101s - loss: 0.0534 - acc: 0.9944 - val_loss: 4.1420 - val_acc: 0.7333
-- Evaluate --
acc: 73.33%
-- Predict --
[[1.000 0.000 0.000]
[0.000 0.000 1.000]
[1.000 0.000 0.000]
[0.000 1.000 0.000]
[1.000 0.000 0.000]
[0.000 1.000 0.000]
[0.000 0.000 1.000]
[0.000 0.000 1.000]
[1.000 0.000 0.000]
[1.000 0.000 0.000]
[1.000 0.000 0.000]
[0.000 0.000 1.000]
[0.000 0.000 1.000]
[1.000 0.000 0.000]
[0.000 0.000 1.000]]
73.33%의 정확도를 얻었습니다. 만족할만한 수준은 아니지만, 도전 시험셋으로 기존 모델을 시험했을 때의 결과가 50%를 못 미치는 수준에 비하면 비약적인 개선이 일어났습니다. 이는 동일한 모델을 사용하면서 훈련 데이터만 부풀려서 학습을 시켰을 뿐인데 성능 향상이 일어났습니다.
결론
원, 삼각형, 사각형을 분류하는 간단한 문제에서도 개발 모델이 현실에 적용하기 위해서는 어떠한 어려움이 있는 지 알게되었습니다. 그리고 이를 극복하는 방안으로 데이터 부풀리기 방법에 대해서 알아보고, 각 파라미터 별로 어떻게 데이터를 부풀리는 지 생성된 이미지를 통해 살펴보왔습니다. 훈련셋이 충분하지 않거나 시험셋의 다양한 특성을 반영되어 있지 않다면 데이터 부풀리기 방법은 성능 개선에 큰 도움을 줄 수 있습니다.
같이 보기
- 강좌 목차
- 이전 : 딥러닝 모델 이야기/컨볼루션 신경망 레이어 이야기
- 다음 : [딥러닝 모델 이야기/순환 신경망 레이어 이야기]
책 소개

[추천사]
- 하용호님, 카카오 데이터사이언티스트 - 뜬구름같은 딥러닝 이론을 블록이라는 손에 잡히는 실체로 만져가며 알 수 있게 하고, 구현의 어려움은 케라스라는 시를 읽듯이 읽어내려 갈 수 있는 라이브러리로 풀어준다.
- 이부일님, (주)인사아트마이닝 대표 - 여행에서도 좋은 가이드가 있으면 여행지에 대한 깊은 이해로 여행이 풍성해지듯이 이 책은 딥러닝이라는 분야를 여행할 사람들에 가장 훌륭한 가이드가 되리라고 자부할 수 있다. 이 책을 통하여 딥러닝에 대해 보지 못했던 것들이 보이고, 듣지 못했던 것들이 들리고, 말하지 못했던 것들이 말해지는 경험을 하게 될 것이다.
- 이활석님, 네이버 클로바팀 - 레고 블럭에 비유하여 누구나 이해할 수 있게 쉽게 설명해 놓은 이 책은 딥러닝의 입문 도서로서 제 역할을 다 하리라 믿습니다.
- 김진중님, 야놀자 Head of STL - 복잡했던 머릿속이 맑고 깨끗해지는 효과가 있습니다.
- 이태영님, 신한은행 디지털 전략부 AI LAB - 기존의 텐서플로우를 활용했던 분들에게 바라볼 수 있는 관점의 전환점을 줄 수 있는 Mild Stone과 같은 책이다.
- 전태균님, 쎄트렉아이 - 케라스의 특징인 단순함, 확장성, 재사용성을 눈으로 쉽게 보여주기 위해 친절하게 정리된 내용이라 생각합니다.
- 유재준님, 카이스트 - 바로 적용해보고 싶지만 어디부터 시작할지 모를 때 최선의 선택입니다.