학습 조기종료 시키기
앞서 ‘학습과정과 데이터셋 이야기’에서 과적합이라는 것을 살펴보았고, 이를 방지하기 위해 조기 종료하는 시점에 대해서 알아보았습니다. 본 절에서는 케라스에서 제공하는 기능을 이용하여 학습 중에 어떻게 조기 종료를 시킬 수 있는 지 알아보겠습니다.
과적합되는 모델 살펴보기
먼저 과적합되는 모델을 만들고 어떻게 학습이 되었는 지 살펴보겠습니다. 아래 코드에서 사용된 데이터수, 배치사이즈, 뉴런 수 등은 과적합 현상을 재현하기 하기 위해 설정된 것으로 실제 최적화된 수치는 아닙니다.
from keras.utils import np_utils
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Activation
import numpy as np
np.random.seed(3)
# 1. 데이터셋 준비하기
# 훈련셋과 시험셋 로딩
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
# 훈련셋과 검증셋 분리
X_val = X_train[50000:]
Y_val = Y_train[50000:]
X_train = X_train[:50000]
Y_train = Y_train[:50000]
X_train = X_train.reshape(50000, 784).astype('float32') / 255.0
X_val = X_val.reshape(10000, 784).astype('float32') / 255.0
X_test = X_test.reshape(10000, 784).astype('float32') / 255.0
# 훈련셋, 검증셋 고르기
train_rand_idxs = np.random.choice(50000, 700)
val_rand_idxs = np.random.choice(10000, 300)
X_train = X_train[train_rand_idxs]
Y_train = Y_train[train_rand_idxs]
X_val = X_val[val_rand_idxs]
Y_val = Y_val[val_rand_idxs]
# 라벨링 전환
Y_train = np_utils.to_categorical(Y_train)
Y_val = np_utils.to_categorical(Y_val)
Y_test = np_utils.to_categorical(Y_test)
# 2. 모델 구성하기
model = Sequential()
model.add(Dense(units=2, input_dim=28*28, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
# 3. 모델 엮기
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
# 4. 모델 학습시키기
hist = model.fit(X_train, Y_train, epochs=3000, batch_size=10, validation_data=(X_val, Y_val))
Train on 700 samples, validate on 300 samples
Epoch 1/3000
700/700 [==============================] - 0s - loss: 2.3067 - acc: 0.1171 - val_loss: 2.2751 - val_acc: 0.0933
Epoch 2/3000
700/700 [==============================] - 0s - loss: 2.2731 - acc: 0.1257 - val_loss: 2.2508 - val_acc: 0.1267
Epoch 3/3000
700/700 [==============================] - 0s - loss: 2.2479 - acc: 0.1343 - val_loss: 2.2230 - val_acc: 0.1267
Epoch 4/3000
700/700 [==============================] - 0s - loss: 2.2220 - acc: 0.1471 - val_loss: 2.1984 - val_acc: 0.1233
Epoch 5/3000
700/700 [==============================] - 0s - loss: 2.1957 - acc: 0.1400 - val_loss: 2.1724 - val_acc: 0.1233
...
# 5. 모델 학습 과정 표시하기
%matplotlib inline
import matplotlib.pyplot as plt
fig, loss_ax = plt.subplots()
acc_ax = loss_ax.twinx()
loss_ax.plot(hist.history['loss'], 'y', label='train loss')
loss_ax.plot(hist.history['val_loss'], 'r', label='val loss')
acc_ax.plot(hist.history['acc'], 'b', label='train acc')
acc_ax.plot(hist.history['val_acc'], 'g', label='val acc')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuray')
loss_ax.legend(loc='upper left')
acc_ax.legend(loc='lower left')
plt.show()
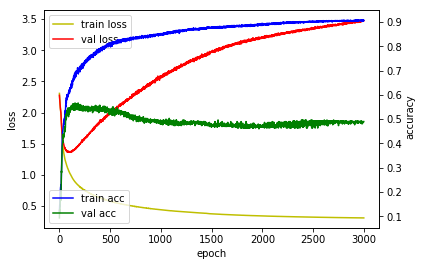
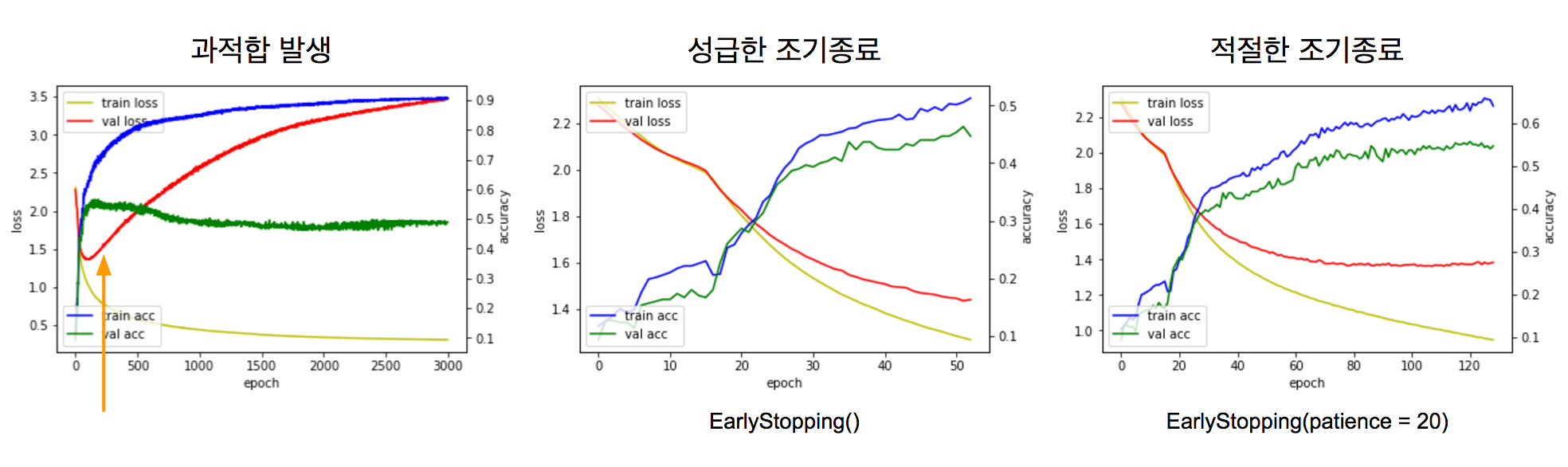
val_loss를 보면 에포크 횟수가 많아질 수록 감소하다가 150 에포크 근처에서 다시 증가됨을 알 수 있습니다. 이때 과적합이 발생한 것 입니다.
# 6. 모델 사용하기
loss_and_metrics = model.evaluate(X_test, Y_test, batch_size=32)
print('')
print('loss : ' + str(loss_and_metrics[0]))
print('accuray : ' + str(loss_and_metrics[1]))
32/10000 [..............................] - ETA: 0s
loss : 3.73021918621
accuray : 0.4499
조기 종료 시키기
학습 조기 종료를 위해서는 ‘EarlyStopping’이라는 함수를 사용하며 더 이상 개선의 여지가 없을 때 학습을 종료시키는 콜백함수입니다. 콜백함수라는 것 어떤 함수를 수행 시 그 함수에서 내가 지정한 함수를 호출하는 것을 말하며, 여기서는 fit 함수에서 EarlyStopping이라는 콜백함수가 학습 과정 중에 매번 호출됩니다. 먼저 fit 함수에서 EarlyStopping 콜백함수를 지정하는 방법은 다음과 같습니다.
early_stopping = EarlyStopping()
model.fit(X_train, Y_train, nb_epoch= 1000, callbacks=[early_stopping])
에포크가 1000으로 지정했더라도 학습 과정에서 EarlyStopping 콜백함수를 호출하여 해당 조건이 되면 학습을 조기 종료시킵니다. EarlyStopping 콜백함수에서 설정할 수 있는 인자는 다음과 같습니다.
keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=0, verbose=0, mode='auto')
- monitor : 관찰하고자 하는 항목입니다. ‘val_loss’나 ‘val_acc’가 주로 사용됩니다.
- min_delta : 개선되고 있다고 판단하기 위한 최소 변화량을 나타냅니다. 만약 변화량이 min_delta보다 적은 경우에는 개선이 없다고 판단합니다.
- patience : 개선이 없다고 바로 종료하지 않고 개선이 없는 에포크를 얼마나 기다려 줄 것인 가를 지정합니다. 만약 10이라고 지정하면 개선이 없는 에포크가 10번째 지속될 경우 학습일 종료합니다.
- verbose : 얼마나 자세하게 정보를 표시할 것인가를 지정합니다. (0, 1, 2)
- mode : 관찰 항목에 대해 개선이 없다고 판단하기 위한 기준을 지정합니다. 예를 들어 관찰 항목이 ‘val_loss’인 경우에는 감소되는 것이 멈출 때 종료되어야 하므로, ‘min’으로 설정됩니다.
- auto : 관찰하는 이름에 따라 자동으로 지정합니다.
- min : 관찰하고 있는 항목이 감소되는 것을 멈출 때 종료합니다.
- max : 관찰하고 있는 항목이 증가되는 것을 멈출 때 종료합니다.
조기 종료 콜백함수를 적용한 코드는 다음과 같습니다.
from keras.utils import np_utils
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Activation
import numpy as np
np.random.seed(3)
# 1. 데이터셋 준비하기
# 훈련셋과 시험셋 로딩
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
# 훈련셋과 검증셋 분리
X_val = X_train[50000:]
Y_val = Y_train[50000:]
X_train = X_train[:50000]
Y_train = Y_train[:50000]
X_train = X_train.reshape(50000, 784).astype('float32') / 255.0
X_val = X_val.reshape(10000, 784).astype('float32') / 255.0
X_test = X_test.reshape(10000, 784).astype('float32') / 255.0
# 훈련셋, 검증셋 고르기
train_rand_idxs = np.random.choice(50000, 700)
val_rand_idxs = np.random.choice(10000, 300)
X_train = X_train[train_rand_idxs]
Y_train = Y_train[train_rand_idxs]
X_val = X_val[val_rand_idxs]
Y_val = Y_val[val_rand_idxs]
# 라벨링 전환
Y_train = np_utils.to_categorical(Y_train)
Y_val = np_utils.to_categorical(Y_val)
Y_test = np_utils.to_categorical(Y_test)
# 2. 모델 구성하기
model = Sequential()
model.add(Dense(units=2, input_dim=28*28, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
# 3. 모델 엮기
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
# 4. 모델 학습시키기
from keras.callbacks import EarlyStopping
early_stopping = EarlyStopping() # 조기종료 콜백함수 정의
hist = model.fit(X_train, Y_train, epochs=3000, batch_size=10, validation_data=(X_val, Y_val), callbacks=[early_stopping])
Train on 700 samples, validate on 300 samples
Epoch 1/3000
700/700 [==============================] - 0s - loss: 2.3067 - acc: 0.1171 - val_loss: 2.2751 - val_acc: 0.0933
Epoch 2/3000
700/700 [==============================] - 0s - loss: 2.2731 - acc: 0.1257 - val_loss: 2.2508 - val_acc: 0.1267
Epoch 3/3000
700/700 [==============================] - 0s - loss: 2.2479 - acc: 0.1343 - val_loss: 2.2230 - val_acc: 0.1267
...
Epoch 51/3000
700/700 [==============================] - 0s - loss: 1.2842 - acc: 0.5014 - val_loss: 1.4463 - val_acc: 0.4533
Epoch 52/3000
700/700 [==============================] - 0s - loss: 1.2760 - acc: 0.5057 - val_loss: 1.4358 - val_acc: 0.4633
Epoch 53/3000
700/700 [==============================] - 0s - loss: 1.2683 - acc: 0.5129 - val_loss: 1.4406 - val_acc: 0.4467
# 5. 모델 학습 과정 표시하기
%matplotlib inline
import matplotlib.pyplot as plt
fig, loss_ax = plt.subplots()
acc_ax = loss_ax.twinx()
loss_ax.plot(hist.history['loss'], 'y', label='train loss')
loss_ax.plot(hist.history['val_loss'], 'r', label='val loss')
acc_ax.plot(hist.history['acc'], 'b', label='train acc')
acc_ax.plot(hist.history['val_acc'], 'g', label='val acc')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuray')
loss_ax.legend(loc='upper left')
acc_ax.legend(loc='lower left')
plt.show()
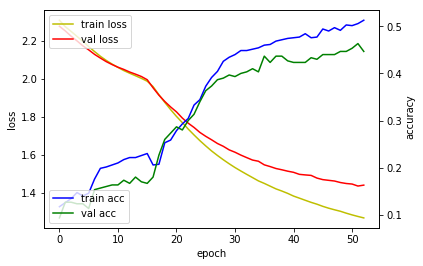
# 6. 모델 사용하기
loss_and_metrics = model.evaluate(X_test, Y_test, batch_size=32)
print('')
print('loss : ' + str(loss_and_metrics[0]))
print('accuray : ' + str(loss_and_metrics[1]))
32/10000 [..............................] - ETA: 0s
loss : 1.439551894
accuray : 0.4443
val_loss 값이 감소되다가 증가되자마자 학습이 종료되었습니다. 하지만 이 모델은 좀 더 학습이 될 수 있는 모델임을 이미 알고 있습니다. val_loss 특성 상 증가/감소를 반복하므로 val_loss가 증가되는 시점에 바로 종료하지말고 지속적으로 증가되는 시점에서 종료해보겠습니다. 이를 위해 EarlyStopping 콜백함수에서 patience 인자를 사용합니다.
early_stopping = EarlyStopping(patience = 20)
즉 증가가 되었더라도 20 에포크 동안은 기다려보도록 지정했습니다. 이를 적용한 코드는 다음과 같습니다.
from keras.utils import np_utils
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Activation
import numpy as np
np.random.seed(3)
# 1. 데이터셋 준비하기
# 훈련셋과 시험셋 로딩
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
# 훈련셋과 검증셋 분리
X_val = X_train[50000:]
Y_val = Y_train[50000:]
X_train = X_train[:50000]
Y_train = Y_train[:50000]
X_train = X_train.reshape(50000, 784).astype('float32') / 255.0
X_val = X_val.reshape(10000, 784).astype('float32') / 255.0
X_test = X_test.reshape(10000, 784).astype('float32') / 255.0
# 훈련셋, 검증셋 고르기
train_rand_idxs = np.random.choice(50000, 700)
val_rand_idxs = np.random.choice(10000, 300)
X_train = X_train[train_rand_idxs]
Y_train = Y_train[train_rand_idxs]
X_val = X_val[val_rand_idxs]
Y_val = Y_val[val_rand_idxs]
# 라벨링 전환
Y_train = np_utils.to_categorical(Y_train)
Y_val = np_utils.to_categorical(Y_val)
Y_test = np_utils.to_categorical(Y_test)
# 2. 모델 구성하기
model = Sequential()
model.add(Dense(units=2, input_dim=28*28, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
# 3. 모델 엮기
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
# 4. 모델 학습시키기
from keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(patience = 20) # 조기종료 콜백함수 정의
hist = model.fit(X_train, Y_train, epochs=3000, batch_size=10, validation_data=(X_val, Y_val), callbacks=[early_stopping])
Train on 700 samples, validate on 300 samples
Epoch 1/3000
700/700 [==============================] - 0s - loss: 2.3067 - acc: 0.1171 - val_loss: 2.2751 - val_acc: 0.0933
Epoch 2/3000
700/700 [==============================] - 0s - loss: 2.2731 - acc: 0.1257 - val_loss: 2.2508 - val_acc: 0.1267
Epoch 3/3000
700/700 [==============================] - 0s - loss: 2.2479 - acc: 0.1343 - val_loss: 2.2230 - val_acc: 0.1267
...
Epoch 127/3000
700/700 [==============================] - 0s - loss: 0.9536 - acc: 0.6557 - val_loss: 1.3753 - val_acc: 0.5467
Epoch 128/3000
700/700 [==============================] - 0s - loss: 0.9494 - acc: 0.6543 - val_loss: 1.3785 - val_acc: 0.5400
Epoch 129/3000
700/700 [==============================] - 0s - loss: 0.9483 - acc: 0.6400 - val_loss: 1.3825 - val_acc: 0.5467
# 5. 모델 학습 과정 표시하기
%matplotlib inline
import matplotlib.pyplot as plt
fig, loss_ax = plt.subplots()
acc_ax = loss_ax.twinx()
loss_ax.plot(hist.history['loss'], 'y', label='train loss')
loss_ax.plot(hist.history['val_loss'], 'r', label='val loss')
acc_ax.plot(hist.history['acc'], 'b', label='train acc')
acc_ax.plot(hist.history['val_acc'], 'g', label='val acc')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuray')
loss_ax.legend(loc='upper left')
acc_ax.legend(loc='lower left')
plt.show()
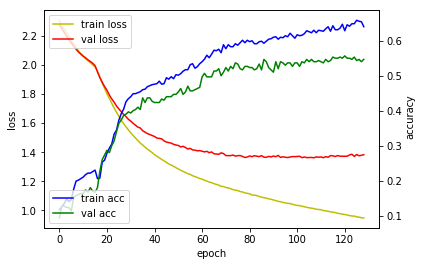
# 6. 모델 사용하기
loss_and_metrics = model.evaluate(X_test, Y_test, batch_size=32)
print('')
print('loss : ' + str(loss_and_metrics[0]))
print('accuray : ' + str(loss_and_metrics[1]))
32/10000 [..............................] - ETA: 0s
loss : 1.34829078026
accuray : 0.5344
모델의 정확도도 향상됨을 확인할 수 있습니다.
요약
본 절에서는 과적합되는 모델을 만들어보고, 조기종료 시키는 방법에 대해서 알아보았습니다. 케라스에서 제공하는 EarlyStopping 콜백함수를 조기종료에 사용해보았고, 설정 인자를 살펴보았습니다.
같이 보기
- 강좌 목차
- 이전 : 학습과정 표시하기 (텐서보드 포함)
- 다음 : 학습 모델 저장하기/불러오기
책 소개

[추천사]
- 하용호님, 카카오 데이터사이언티스트 - 뜬구름같은 딥러닝 이론을 블록이라는 손에 잡히는 실체로 만져가며 알 수 있게 하고, 구현의 어려움은 케라스라는 시를 읽듯이 읽어내려 갈 수 있는 라이브러리로 풀어준다.
- 이부일님, (주)인사아트마이닝 대표 - 여행에서도 좋은 가이드가 있으면 여행지에 대한 깊은 이해로 여행이 풍성해지듯이 이 책은 딥러닝이라는 분야를 여행할 사람들에 가장 훌륭한 가이드가 되리라고 자부할 수 있다. 이 책을 통하여 딥러닝에 대해 보지 못했던 것들이 보이고, 듣지 못했던 것들이 들리고, 말하지 못했던 것들이 말해지는 경험을 하게 될 것이다.
- 이활석님, 네이버 클로바팀 - 레고 블럭에 비유하여 누구나 이해할 수 있게 쉽게 설명해 놓은 이 책은 딥러닝의 입문 도서로서 제 역할을 다 하리라 믿습니다.
- 김진중님, 야놀자 Head of STL - 복잡했던 머릿속이 맑고 깨끗해지는 효과가 있습니다.
- 이태영님, 신한은행 디지털 전략부 AI LAB - 기존의 텐서플로우를 활용했던 분들에게 바라볼 수 있는 관점의 전환점을 줄 수 있는 Mild Stone과 같은 책이다.
- 전태균님, 쎄트렉아이 - 케라스의 특징인 단순함, 확장성, 재사용성을 눈으로 쉽게 보여주기 위해 친절하게 정리된 내용이라 생각합니다.
- 유재준님, 카이스트 - 바로 적용해보고 싶지만 어디부터 시작할지 모를 때 최선의 선택입니다.