코랩 시작하기
파이썬, 머신러닝, 딥러닝 등등을 하려면 콘솔 화면(해커 영화에서 보이는 시커먼 배경의 녹색 글씨 화면)이거나 주피터(웹 브라우져 상에서 코딩 가능) 환경을 구축을 해야하는 데, 이 환경 구축이 입문자들에게는 만만치 않은 작업입니다. 숙련자에게도 여전히 어려운 것이 무엇이냐고 물어보면 ‘환경 구축’이라고 말할 정도로 쉽지 않습니다. 구글에서는 이러한 환경 구축을 하지 않고도 클라우드 환경에서 쉽게 할 수 있도록 “Colab(코랩)”을 제공하고 있습니다. 제공 형식은 주피터 노트북이라 기본적인 조작법은 익혀야 되지만 크게 어렵지는 않습니다.
아래 링크에서 시작할 수 있습니다.
https://colab.research.google.com/
코랩에선 파이썬을 자유롭게 코딩할 수 있고, 텐서플로우나 케라스 등 딥러닝 라이브러리도 쉽게 사용할 수 있습니다. 데이터 관련 처리를 하다보면 자신의 데이터를 클라우드 상에서 올려서 테스트 해야할 때가 있습니다. 로컬 디스크에서 코랩 클라우드 상에 바로 업로드 하는 방법과 구글 드라이브 상에 올린다음 연동 후 사용하는 방법에 대해 알아보겠습니다.
파일 업로드 하기
코랩은 클라우드 상(즉 어딘가에 인터넷에 연결된 구글 서버)에서 실행되기 때문에 코랩에서 내 파일을 이용하려면, 코랩 클라우드에 내 파일을 업로드를 해야합니다. 코랩 주피터 노트북에서 아래 두 줄로 간단하게 업로드를 할 수 있습니다.
from google.colab import files
uploaded = files.upload()
실행시키면 아래 그림처럼 “파일 선택” 버튼이 표시되고, 이 버튼을 클릭하면 내 컴퓨터에 있는 파일을 선택할 수 있는 창이 띄워집니다.

원하는 파일을 선택한 후 아래 “열기” 버튼을 클릭합니다.
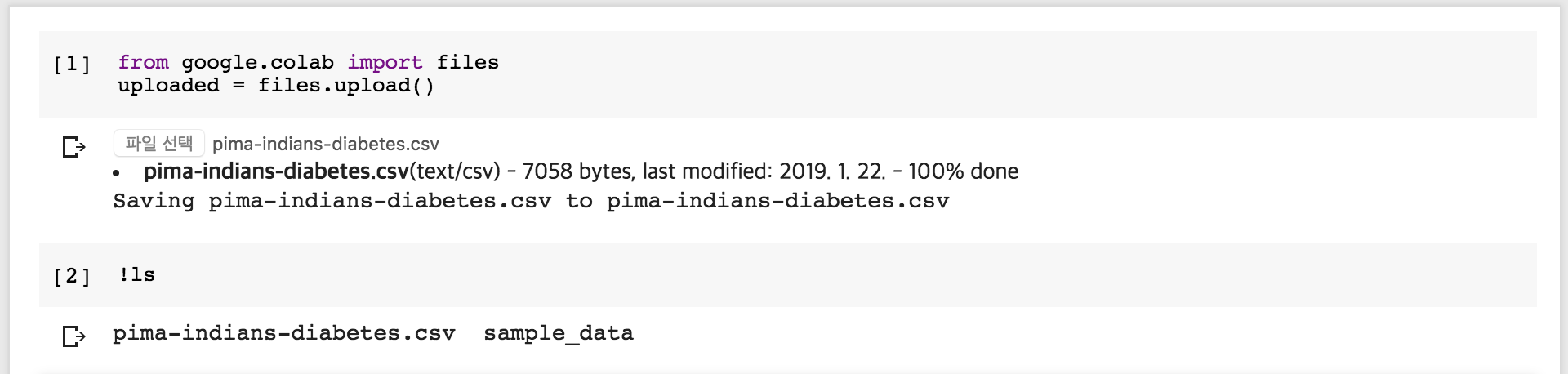
업로드 과정이 화면에 표시되며, 정상적으로 업로드가 되면 “!ls” 명령어로 클라우드 상에 있는 스토리지에 해당 파일이 보이는 지 확인합니다.
numpy 패키지를 이용해서 파일을 열어서 정상적으로 데이터가 로딩되는 지 확인합니다. “pima-indians-diabetes.csv” 파일은 쉽표(,)로 구분된 9개의 항목을 가진 파일로 numpy 패키지의 loadtxt() 함수로 쉽게 로딩할 수 있습니다. “pima-indians-diabetes.csv” 파일을 다운로드 받으시려면 여기을 클릭하세요.
import numpy as np
dataset = np.loadtxt("pima-indians-diabetes.csv", delimiter=",")
print(dataset)
[[ 6. 148. 72. 1.]
[ 1. 85. 66. 0.]
[ 8. 183. 64. 1.]
...
[ 1. 89. 24. 0.]
[ 1. 173. 74. 1.]
[ 1. 109. 38. 0.]]
정상적으로 파일을 읽어들여서 numpy 형태의 배열로 저장됨을 확인할 수 있습니다.
코랩 클라우드 상에 업로드 된 파일은 일정시간이 지나면 자동으로 삭제됩니다.
구글 드라이브 연동하기
코랩 클라우드에 파일을 업로드하는 방식은 파일이 삭제되면 다시 업로드를 해야하므로, 지속적으로 테스트하기에는 번거로움이 있습니다. 특정 파일을 계속 사용할 경우 구글 드라이브에 파일을 업로드 한 후에 연동하는 방식을 추천드립니다. 주피터 노트북에서 아래 두 줄로 구글 드라이브와 연동할 수 있습니다.
from google.colab import drive
drive.mount('/gdrive', force_remount=True)
실행하면 클릭할 수 있는 링크가 보이고, 인증 코드를 입력하는 란이 표시됩니다.

먼저 링크를 선택하면 구글 계정에 로그인하라는 창이 띄워집니다. 만약 구글 계정이 없으시다면 먼저 계정을 생성하세요.
연동하고자 하는 구글 계정을 선택하면 구글 드라이브에 접근할 수 있는 권한에 대해서 물어봅니다. “허용” 버튼을 클릭합니다.
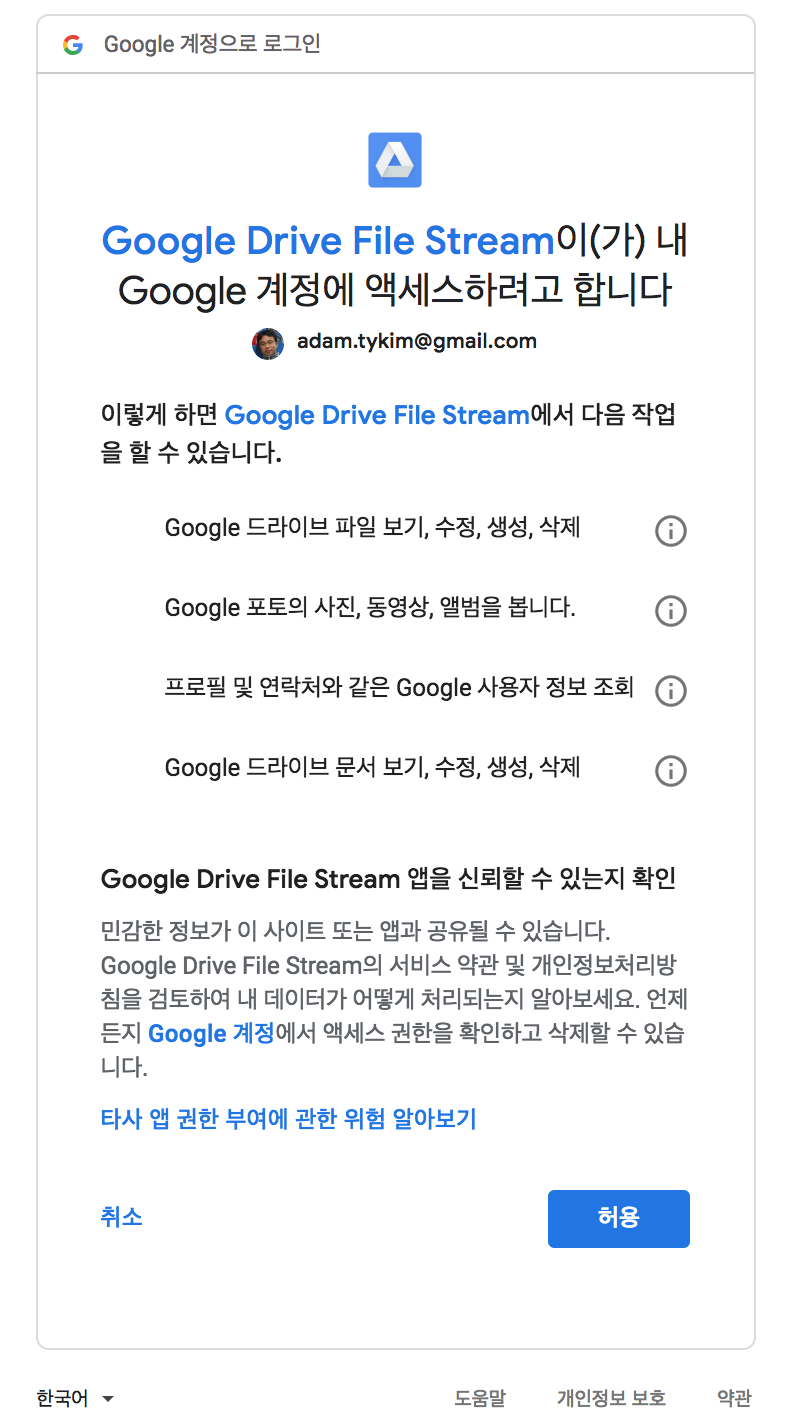
정상적으로 진행되면 인증 코드가 표시되며, 이 코드를 복사합니다.
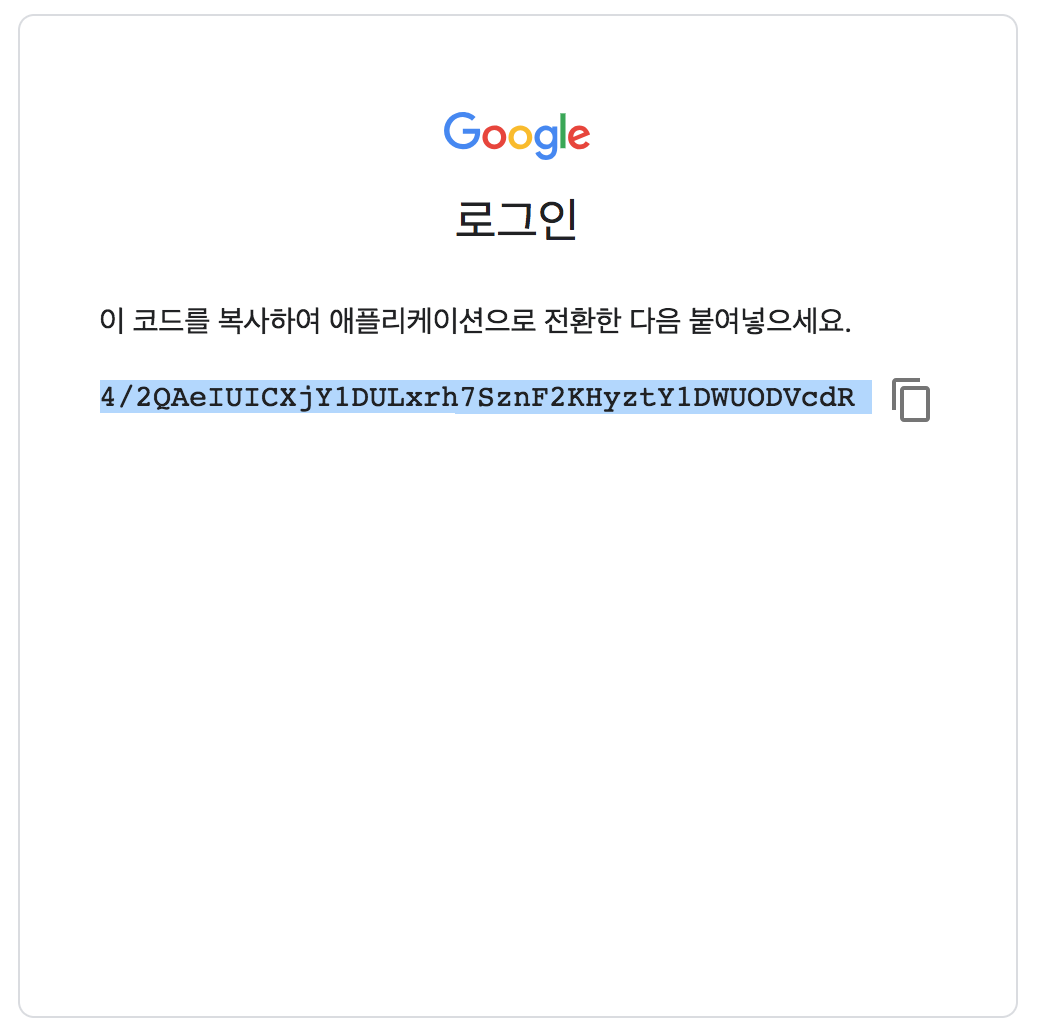
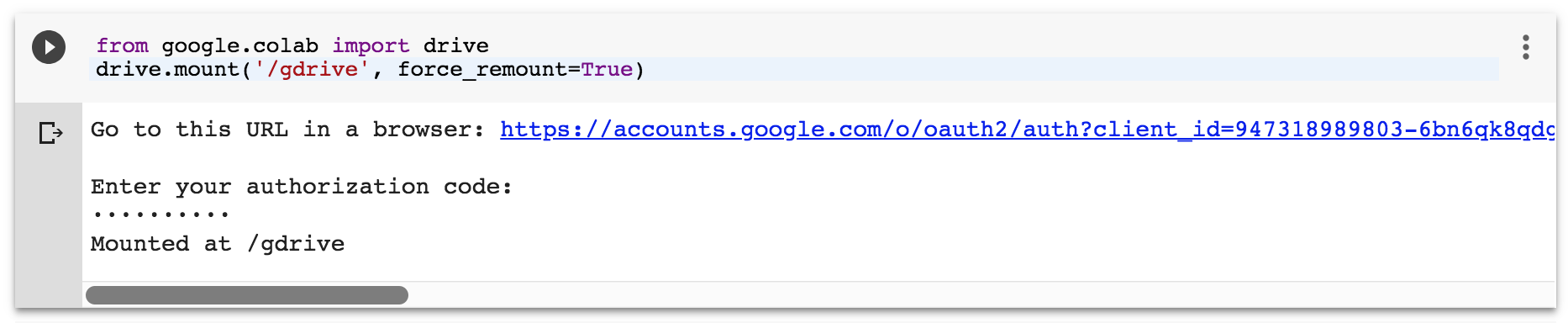
복사한 코드를 인증 코드를 입력하는 란에 붙인 후 엔터 키를 누르면 인증 절차가 시작되고, 정상적으로 인증되면 아래 그림처럼 “Mounted at /grive”이라는 메시지가 띄워집니다.
본격적으로 드라이브에 파일을 업로드하기 전에 구글 드라이브의 설정을 확인해봅니다.
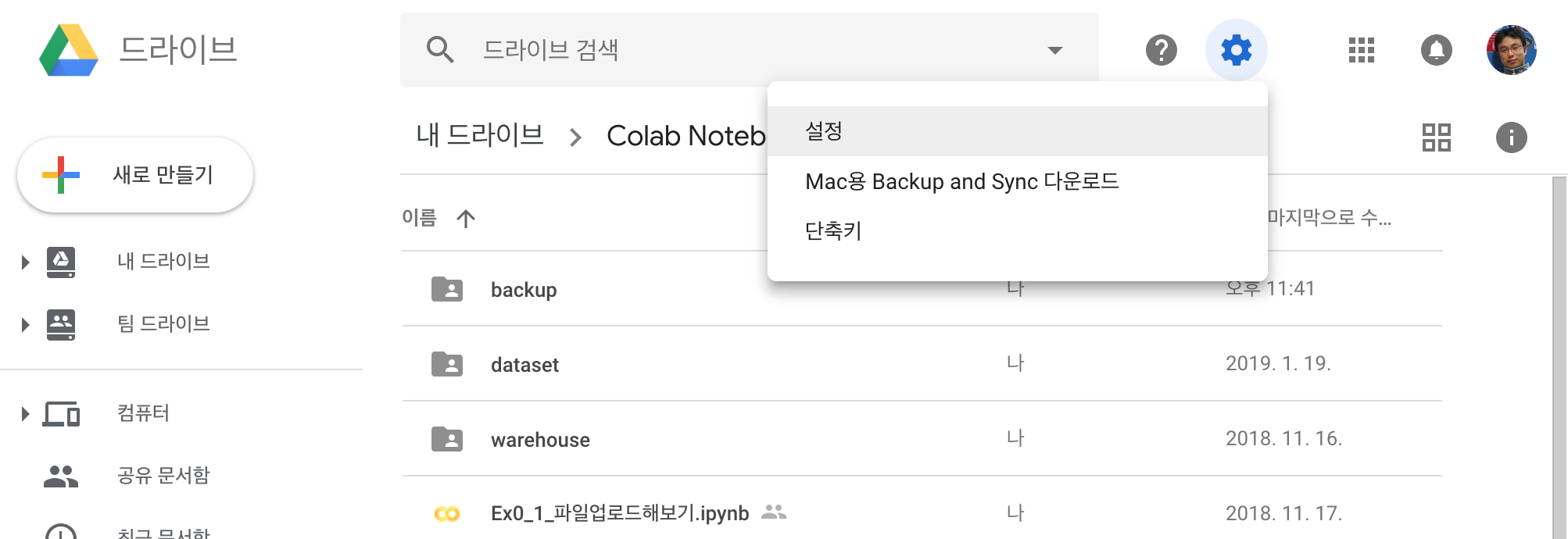
설정 화면에서 “업로드 변환” 옵션이 꺼져 있는 지 확인합니다. 만약 체크되어 있다면, 체크를 해제하여 업로드하는 파일이 구글 문서로 변환되지 않도록 합니다.
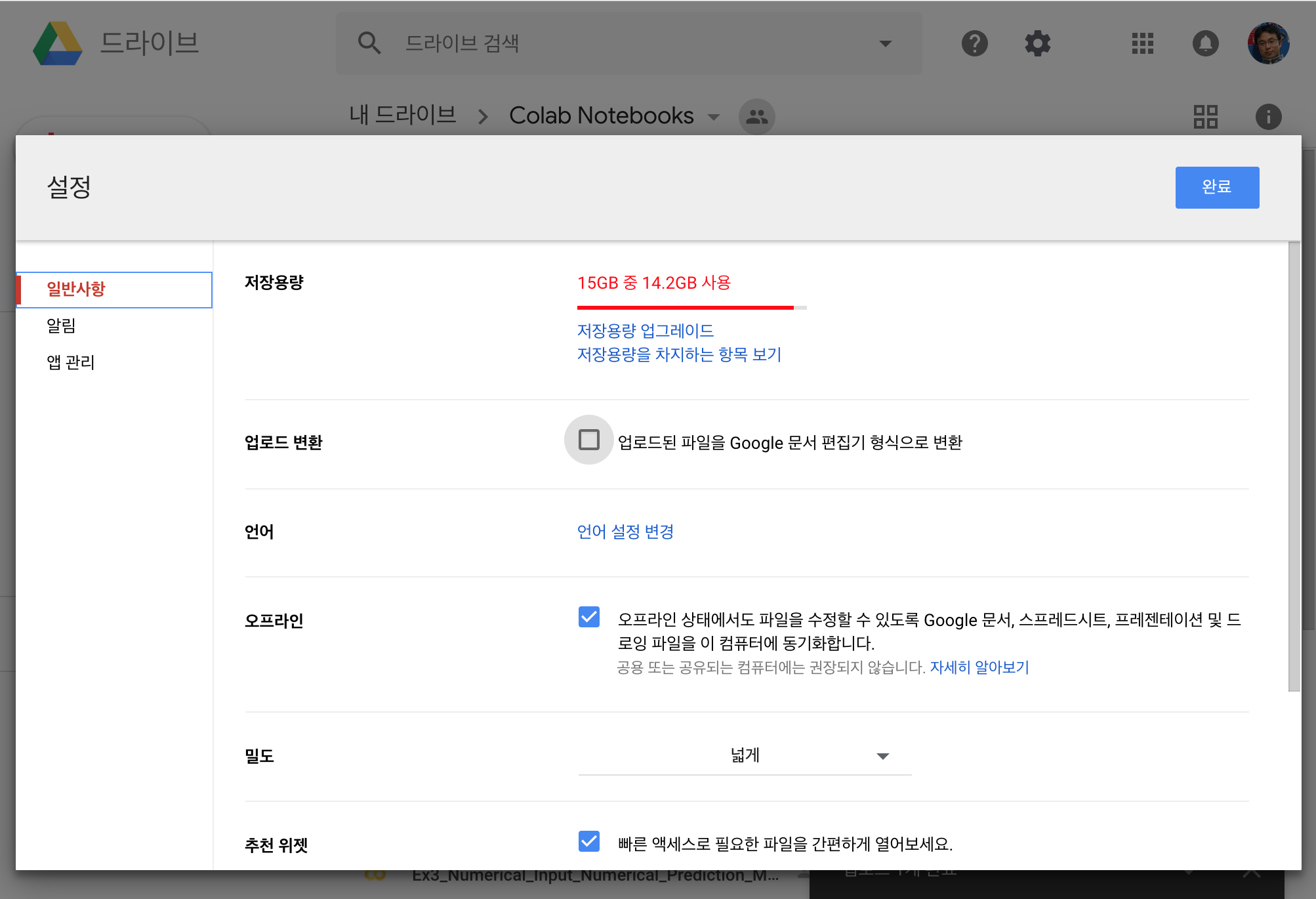
설정 확인까지 마쳤다면, 아래 그림처럼 “파일 업로드” 메뉴를 선택합니다.
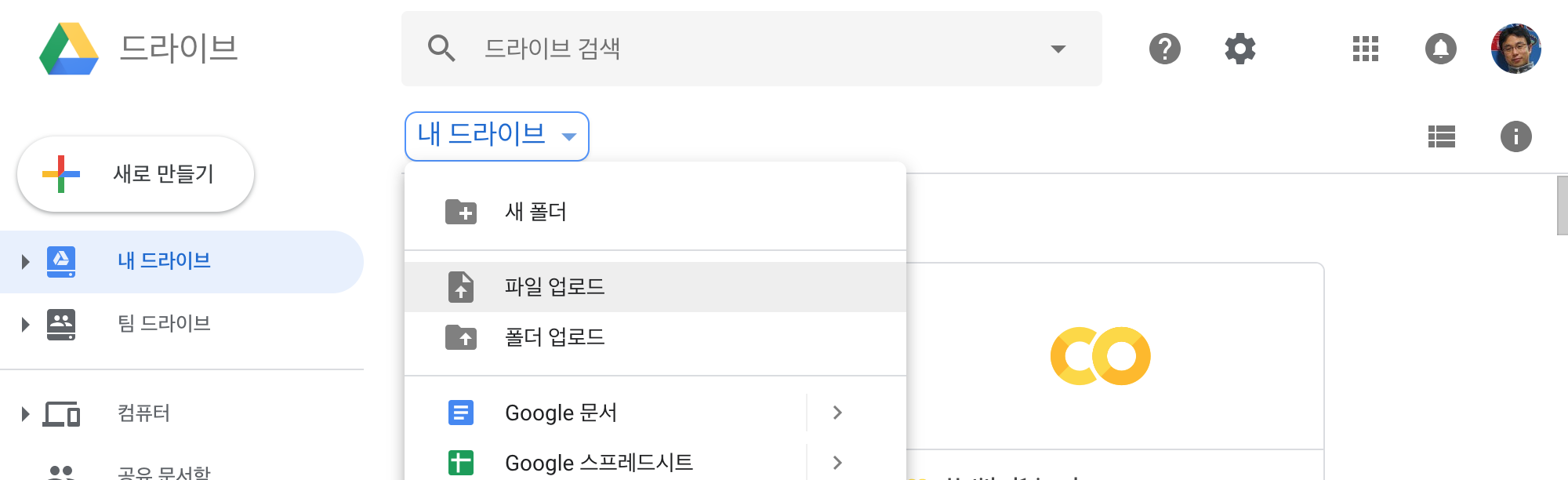
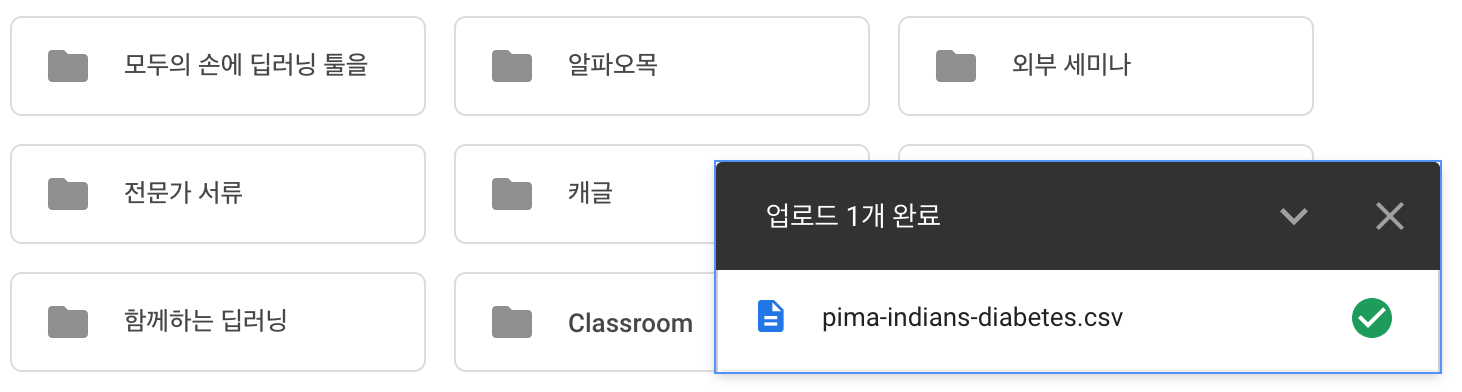
내 컴퓨터에서 파일을 선택하는 창이 띄워지고, 원하는 파일을 선택하면 업로드가 시작됩니다. 업로드 과정은 우측 하단의 메시지 창에서 확인할 수 있으며, 정상적으로 업로드가 되면 완료 메시지가 띄워집니다.
코랩 주피터 노트북에서도 아래 명령으로 구글 드라이브 파일 목록을 확인할 수 있습니다.
!ls "/gdrive/My Drive"
파일이 확인이 되면 아래 코드로 구글 드라이브에 있는 파일을 읽어봅니다. 구글 드라이브에서 “내 드라이브”의 경로는 “/gdrive/My Drive/”의 경로이기 때문에 내 드라이브에 있는 파일을 선택할 경우 파일명 앞에 “/gdrive/My Drive/”을 붙입니다.
import numpy as np
dataset = np.loadtxt("/gdrive/My Drive/pima-indians-diabetes.csv", delimiter=",")
print(dataset)
위 코드가 정상적으로 실행되면 파일에서 로딩된 데이터 값이 화면에 표시됩니다.
[[ 6. 148. 72. 1.]
[ 1. 85. 66. 0.]
[ 8. 183. 64. 1.]
...
[ 1. 89. 24. 0.]
[ 1. 173. 74. 1.]
[ 1. 109. 38. 0.]]
마무리
코랩이 클라우드에서 동작되기 때문에 가장 궁금증이 생길 수 있는 부분인 ‘내 파일 연동하기’에 대해서 직접 파일을 업로드하는 방식과 구글 드라이브와 연동하는 방식에 대해서 알아보았습니다. 이 밖에도 코랩에서는 데이터 연동하는 부분에 대해서 다양한 방법이 지원되고 있으니 아래 링크를 참고하세요.
같이 보기
책 소개

[추천사]
- 하용호님, 카카오 데이터사이언티스트 - 뜬구름같은 딥러닝 이론을 블록이라는 손에 잡히는 실체로 만져가며 알 수 있게 하고, 구현의 어려움은 케라스라는 시를 읽듯이 읽어내려 갈 수 있는 라이브러리로 풀어준다.
- 이부일님, (주)인사아트마이닝 대표 - 여행에서도 좋은 가이드가 있으면 여행지에 대한 깊은 이해로 여행이 풍성해지듯이 이 책은 딥러닝이라는 분야를 여행할 사람들에 가장 훌륭한 가이드가 되리라고 자부할 수 있다. 이 책을 통하여 딥러닝에 대해 보지 못했던 것들이 보이고, 듣지 못했던 것들이 들리고, 말하지 못했던 것들이 말해지는 경험을 하게 될 것이다.
- 이활석님, 네이버 클로바팀 - 레고 블럭에 비유하여 누구나 이해할 수 있게 쉽게 설명해 놓은 이 책은 딥러닝의 입문 도서로서 제 역할을 다 하리라 믿습니다.
- 김진중님, 야놀자 Head of STL - 복잡했던 머릿속이 맑고 깨끗해지는 효과가 있습니다.
- 이태영님, 신한은행 디지털 전략부 AI LAB - 기존의 텐서플로우를 활용했던 분들에게 바라볼 수 있는 관점의 전환점을 줄 수 있는 Mild Stone과 같은 책이다.
- 전태균님, 쎄트렉아이 - 케라스의 특징인 단순함, 확장성, 재사용성을 눈으로 쉽게 보여주기 위해 친절하게 정리된 내용이라 생각합니다.
- 유재준님, 카이스트 - 바로 적용해보고 싶지만 어디부터 시작할지 모를 때 최선의 선택입니다.