FormNet - Google AI
양식 문서는 특정 형식으로 구조화시킨 것이지만, 양식 문서를 인식하는 것은 그 형식이 다양하기 때문에 대표적인 비정형데이터라고 보실 수 있습니다. 양식 문서 중에는 표, 텍스트 (심지어 이미지까지) 개체들이 복잡하게 구성된 레이아웃이 많아서 양식 문서 인식은 어려운 문제 중 하나였습니다. 구글에서는 “FormNet: Structural Encoding Beyond Sequential Modeling in Form Document Information Extraction”이란 연구를 ACL 2022에서 발표했습니다.
※ 본 글은 Google AI Blog의 FormNet: Beyond Sequential Modeling for Form-Based Document Understanding 게시물에서 요약한 것입니다.
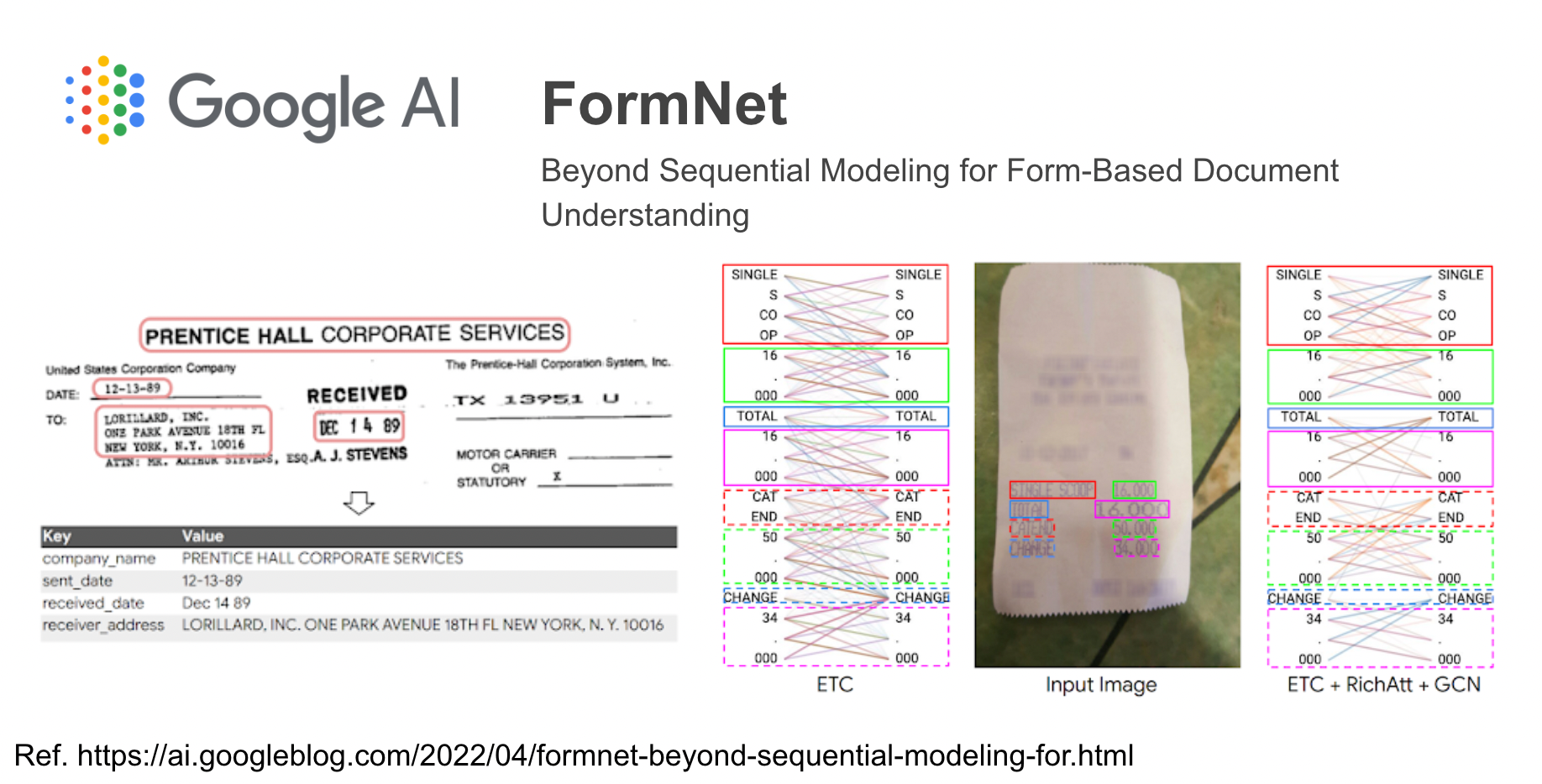
FormNet은 아래 순서로 처리됩니다.
- 단어 식별과 토큰화 : 주어진 양식 문서에서 BERT-multilingual 사전과 OCR (광학 문자 인식)을 이용하여 단어를 식별하고 토큰화를 수행합니다.

- 그래프 구성 및 메시지 패싱 : 식별한 토큰과 2D 좌표를 GCN에 전달합니다.

- 의미있는 엔터티 추출 : 스키마 학습을 위해 GCN으로 인코딩된 구조화시킨 토큰을 Rich Attention (RichAtt) 매커니즘으로 처리합니다.

- 최종 엔터티 추출 및 디코딩 : Viterbi 알고리즘을 이용하여 사후확률을 최대화시키는 시퀀스를 찾아냅니다.
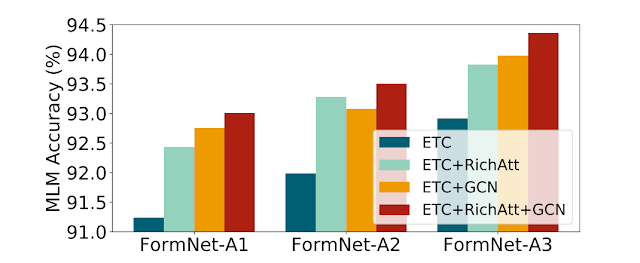
ETC, ETC+RichAtt, ETC+GCN, ETC+RichAtt+GCN 이렇게 4개의 모델로 Masked-Language Modeling(MLM) 사전 훈련 성능 평가를 한 결과라고 합니다. ETC+RichAtt+GCN 모델이 다른 모델보다 성능 개선이 많이 되었네요.
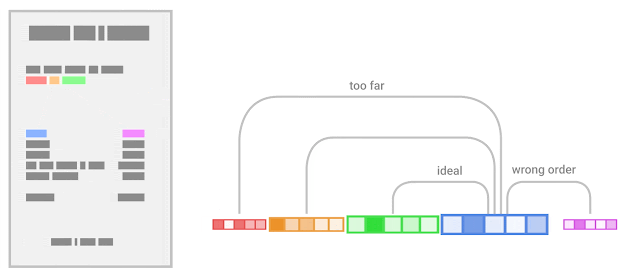
기존 모델보다 크게 개선되었다고 하니 양식 인식이 필요하신 분들은 한 번 살펴보시면 좋을 것 같습니다.
책 소개

[추천사]
- 하용호님, 카카오 데이터사이언티스트 - 뜬구름같은 딥러닝 이론을 블록이라는 손에 잡히는 실체로 만져가며 알 수 있게 하고, 구현의 어려움은 케라스라는 시를 읽듯이 읽어내려 갈 수 있는 라이브러리로 풀어준다.
- 이부일님, (주)인사아트마이닝 대표 - 여행에서도 좋은 가이드가 있으면 여행지에 대한 깊은 이해로 여행이 풍성해지듯이 이 책은 딥러닝이라는 분야를 여행할 사람들에 가장 훌륭한 가이드가 되리라고 자부할 수 있다. 이 책을 통하여 딥러닝에 대해 보지 못했던 것들이 보이고, 듣지 못했던 것들이 들리고, 말하지 못했던 것들이 말해지는 경험을 하게 될 것이다.
- 이활석님, 네이버 클로바팀 - 레고 블럭에 비유하여 누구나 이해할 수 있게 쉽게 설명해 놓은 이 책은 딥러닝의 입문 도서로서 제 역할을 다 하리라 믿습니다.
- 김진중님, 야놀자 Head of STL - 복잡했던 머릿속이 맑고 깨끗해지는 효과가 있습니다.
- 이태영님, 신한은행 디지털 전략부 AI LAB - 기존의 텐서플로우를 활용했던 분들에게 바라볼 수 있는 관점의 전환점을 줄 수 있는 Mild Stone과 같은 책이다.
- 전태균님, 쎄트렉아이 - 케라스의 특징인 단순함, 확장성, 재사용성을 눈으로 쉽게 보여주기 위해 친절하게 정리된 내용이라 생각합니다.
- 유재준님, 카이스트 - 바로 적용해보고 싶지만 어디부터 시작할지 모를 때 최선의 선택입니다.