챗GPT로 머신러닝 모델 만들기
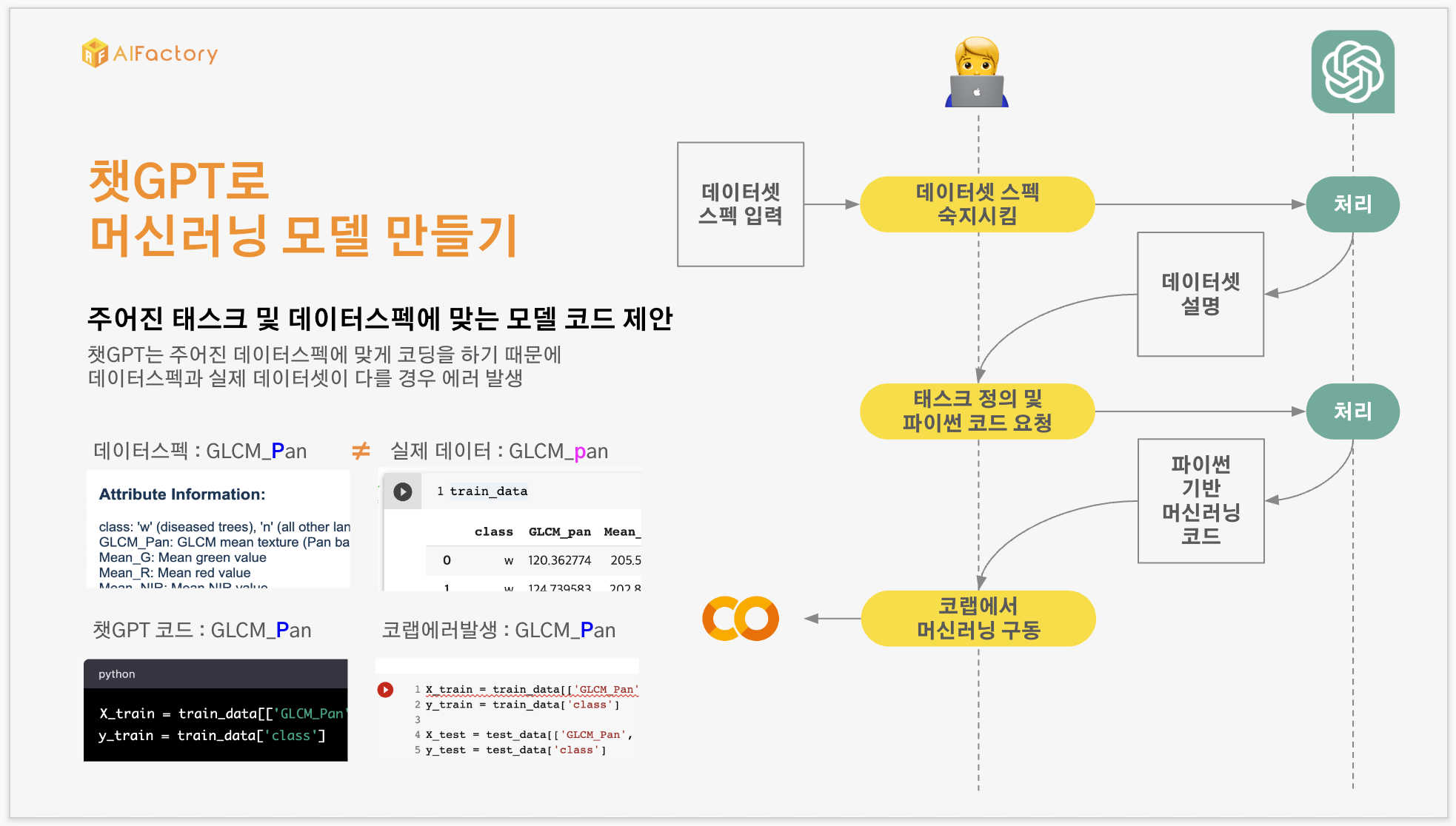
이번에는 챗GPT로 머신러닝 모델 개발을 요청해보도록 하겠습니다. 전체 시나리오는 다음과 같습니다.
- 데이터셋을 추천받고 데이터셋 스팩 숙지 및 요약을 시킵니다.
- 데이터셋을 기반으로 태스크 정의 및 파이썬 코드를 요청합니다.
- 받은 코드를 코랩에서 구동시켜봅니다.
전체 시리즈는 타이키모스 블로그에서 보실 수 있습니다. »
프롬프트와 답변
이번 시나리오에 사용된 프롬프트 및 답변을 가지고 왔습니다. 팁이나 추가 설명이 필요할 경우 아래 서식을 이용했습니다.
팁 혹은 추가설명

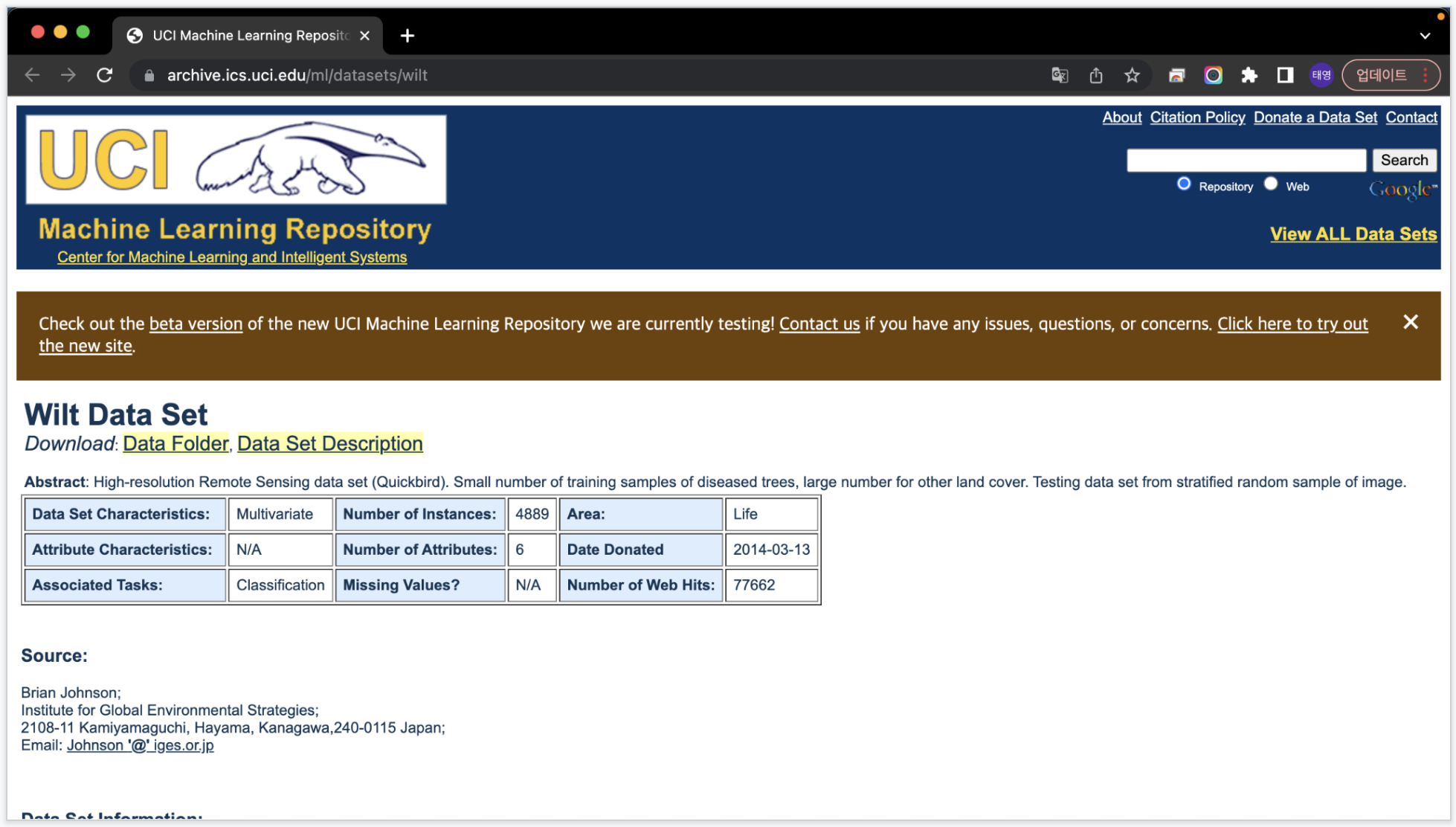
소나무재선충병과 관련된 데이터셋을 다운로드 받을 수 있는 사이트를 알려줘.

소나무재선충병과 관련된 데이터셋을 다운로드 받을 수 있는 사이트는 UCI Machine Learning Repository입니다. 해당 데이터셋의 이름은 “Wilt Data Set”이며, 아래 링크에서 다운로드 받을 수 있습니다.
[https://archive.ics.uci.edu/ml/datasets/wilt](https://archive.ics.uci.edu/ml/datasets/wilt)
아래 데이터셋에 대해서 한국어로 쉽게 설명해줘.
Wilt Data Set
Download: Data Folder, Data Set Description
Abstract: High-resolution Remote Sensing data set (Quickbird). Small number of training samples of diseased trees, large number for other land cover. Testing data set from stratified random sample of image.
(생략)
Data Set Information:
This data set contains some training and testing data from a remote sensing study by Johnson et al. (2013) that involved detecting diseased trees in Quickbird imagery. There are few training samples for the ‘diseased trees’ class (74) and many for ‘other land cover’ class (4265).
The data set consists of image segments, generated by segmenting the pansharpened image. The segments contain spectral information from the Quickbird multispectral image bands and texture information from the panchromatic (Pan) image band. The testing data set is for the row with “Segmentation scale 15†segments and “original multi-spectral image†Spectral information in Table 2 of the reference (i.e. row 5). Please see the reference below for more information on the data set, and please cite the reference if you use this data set. Enjoy!
Files
training.csv: training data set (4339 image segments)
testing.csv: testing data set (500 image segments)
(생략)
이 데이터셋은 Quickbird 이미지에서 질병에 걸린 나무를 감지하는 원격 감지 연구에서 사용된 데이터셋입니다. 이 데이터셋은 다양한 분광 대역에서 파생된 스펙트럴 정보와 Panchromatic 이미지 대역에서 파생된 질감 정보를 포함한 이미지 세그먼트로 구성되어 있습니다. 클래스는 ‘w’로 표시되는 질병에 걸린 나무와 ‘n’으로 표시되는 기타 지형 피복 지역으로 구성됩니다. 이 데이터셋은 훈련 데이터셋(4339개 이미지 세그먼트)과 테스트 데이터셋(500개 이미지 세그먼트)으로 나뉘어져 있습니다. 이 데이터셋은 학술 연구를 위해 사용될 수 있으며, 데이터셋을 사용하면 이 데이터셋의 출처를 인용해야 합니다.
아래는 https://archive.ics.uci.edu/ml/datasets/wilt 에서 제공하는 소나무 데이터셋 정보야. ‘w’ (diseased trees), ‘n’ (all other land cover) 클래스를 분류하는 머신러닝 파이썬 코드를 작성해줘.
(생략)
Files
training.csv: training data set (4339 image segments)
testing.csv: testing data set (500 image segments)
Attribute Information:
class: ‘w’ (diseased trees), ‘n’ (all other land cover)
GLCM_Pan: GLCM mean texture (Pan band)
Mean_G: Mean green value
Mean_R: Mean red value
Mean_NIR: Mean NIR value
SD_Pan: Standard deviation (Pan band)
(생략)
머신러닝 분류 모델 코드를 작성해보겠습니다. 필요한 라이브러리를 불러옵니다.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
데이터를 불러옵니다.
train_data = pd.read_csv("training.csv")
test_data = pd.read_csv("testing.csv")
필요한 데이터만 선택합니다.
X_train = train_data[['GLCM_Pan', 'Mean_G', 'Mean_R', 'Mean_NIR', 'SD_Pan']]
y_train = train_data['class']
X_test = test_data[['GLCM_Pan', 'Mean_G', 'Mean_R', 'Mean_NIR', 'SD_Pan']]
y_test = test_data['class']
학습용 데이터를 더 작은 학습용 데이터와 검증용 데이터로 나눕니다.
X_train_small, X_val, y_train_small, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
랜덤 포레스트 모델을 학습시킵니다.
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train_small, y_train_small)
검증용 데이터를 이용하여 정확도를 계산합니다.
val_predictions = model.predict(X_val)
val_accuracy = accuracy_score(y_val, val_predictions)
print(f"Validation Accuracy: {val_accuracy:.2f}")
최종 모델을 학습용 데이터 전체를 이용하여 재학습시키고, 테스트 데이터를 이용하여 정확도를 계산합니다.
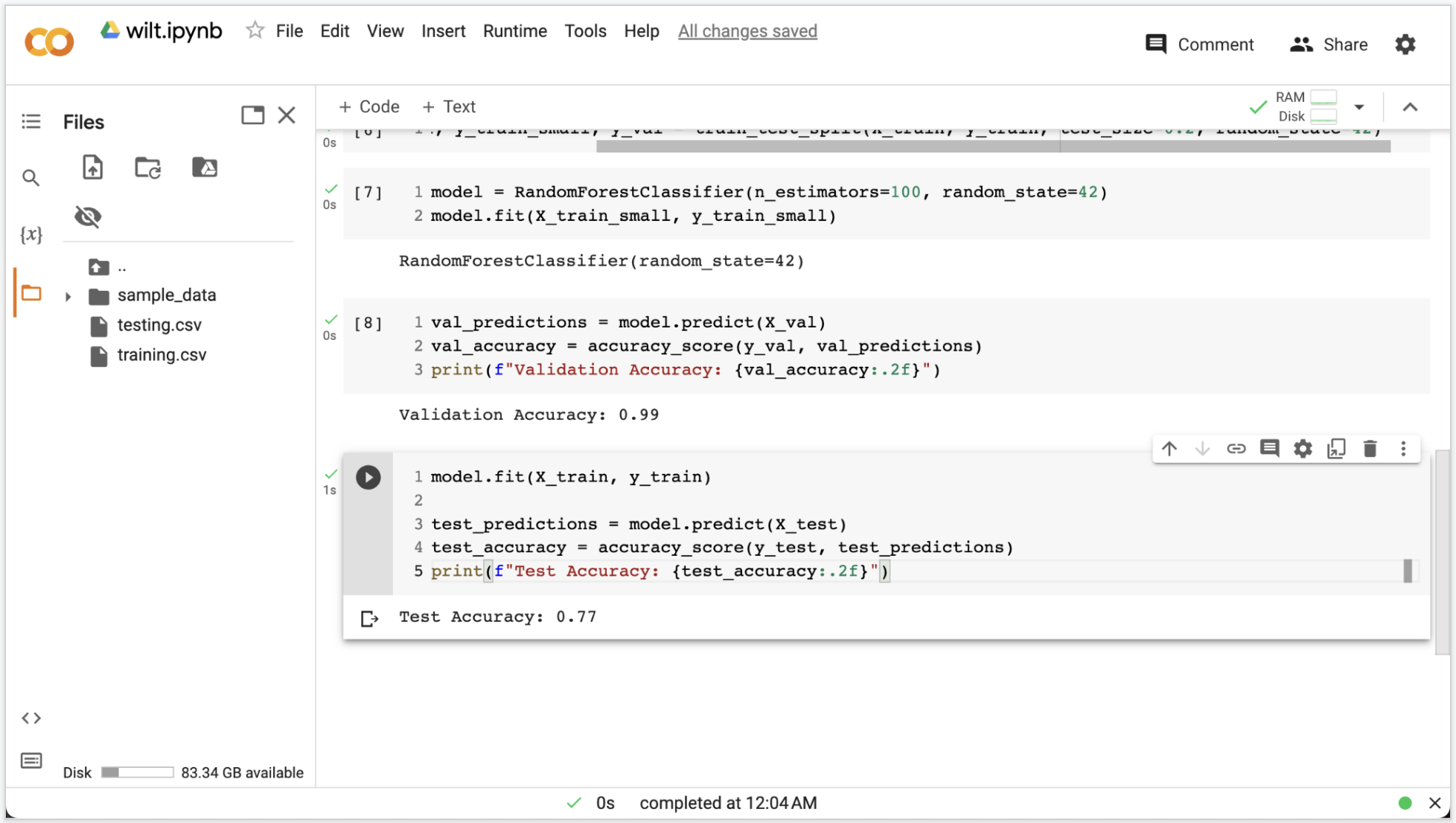
model.fit(X_train, y_train)
test_predictions = model.predict(X_test)
test_accuracy = accuracy_score(y_test, test_predictions)
print(f"Test Accuracy: {test_accuracy:.2f}")
여기까지가 머신러닝 모델 코드입니다. 이제 이 코드를 실행시키면 소나무 데이터셋에서 ‘w’ 클래스와 ‘n’ 클래스를 분류하는 모델이 학습됩니다.
따라해보기
챗GPT가 만들어준 코드를 코랩에서 구동시켜보겠습니다. train_data 데이터를 읽는 부분에서 에러가 발생하네요.
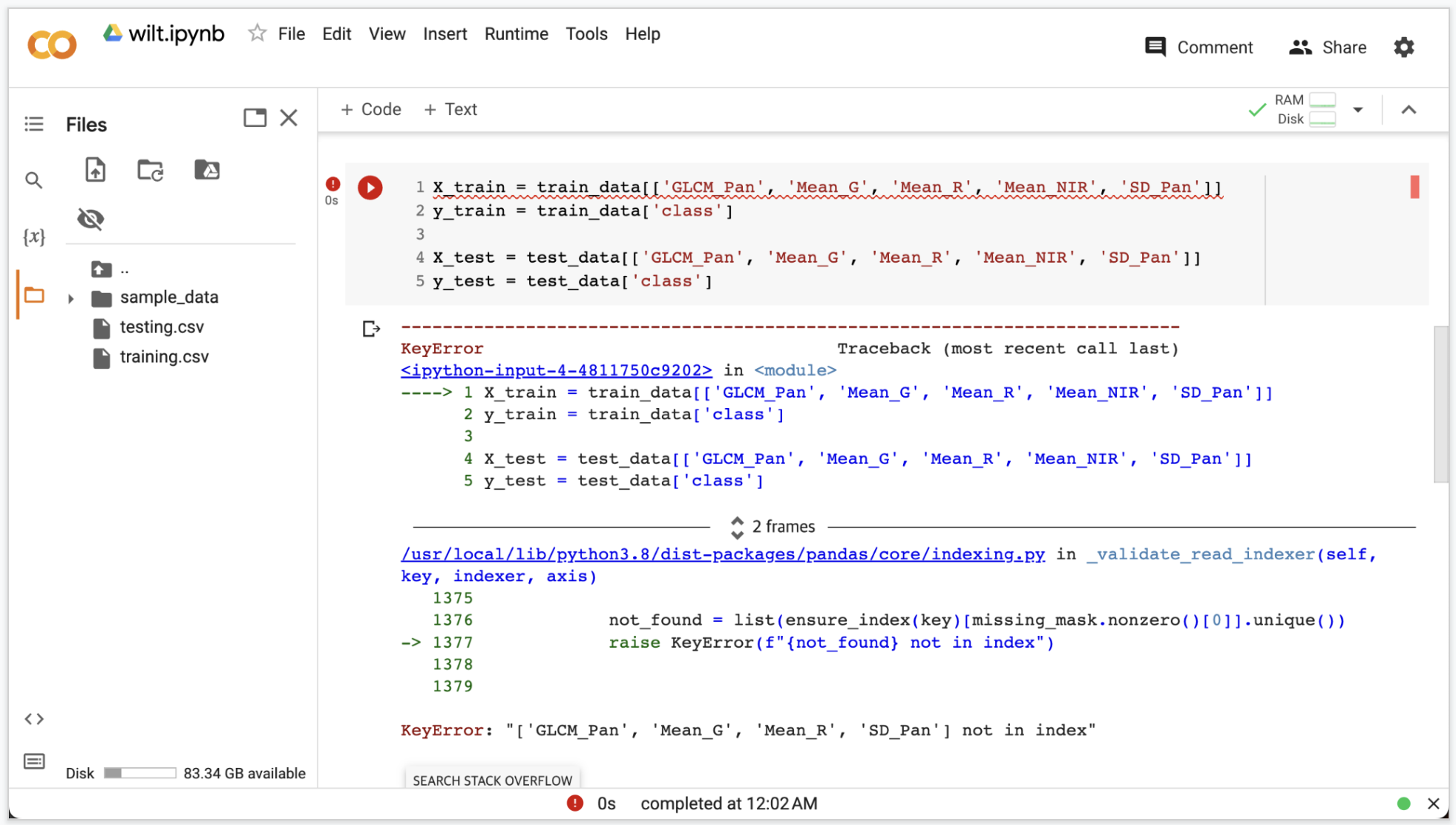
그래서 실제 데이터를 확인해보니, 컬럼명이 다르게 들어가 있네요. 데이터셋 스펙에 나와있는 컬럼명과 실제 데이터 파일에 있는 컬럼명이 달라서 발생한 오류이네요.
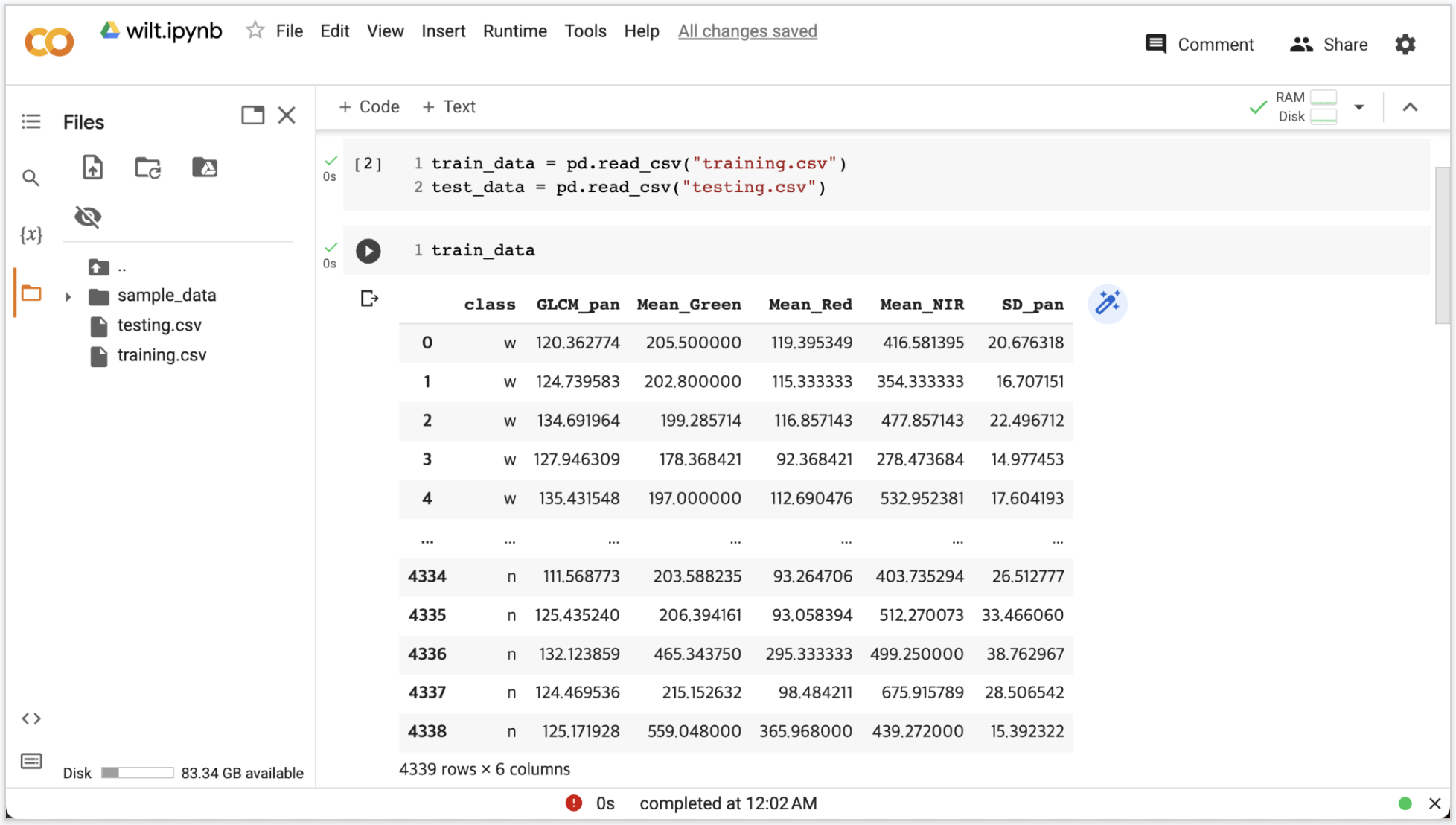
실제 데이터 파일에 맞게 컬럼명을 수정하니 정상적으로 작동을 합니다. 검증셋 정확도 99%, 테스트셋 정확도 77%의 결과를 얻었습니다.
결론
챗GPT를 통해 머신러닝 모델 코드를 작성해봤습니다. 주어진 데이터 스팩에 맞게 코드를 작성하다보니, 스펙과 실제 데이터가 다르니 에러가 발생합니다. 랜덤포레스트 분류기를 사용한 간단한 모델이었지만, 검증셋과 시험셋을 나누어 평가를 제대로 하는 코드를 작성했습니다. 머신러닝이나 딥러닝 분에서도 많은 도움을 얻을 수 있을 것 같습니다.
책 소개

[추천사]
- 하용호님, 카카오 데이터사이언티스트 - 뜬구름같은 딥러닝 이론을 블록이라는 손에 잡히는 실체로 만져가며 알 수 있게 하고, 구현의 어려움은 케라스라는 시를 읽듯이 읽어내려 갈 수 있는 라이브러리로 풀어준다.
- 이부일님, (주)인사아트마이닝 대표 - 여행에서도 좋은 가이드가 있으면 여행지에 대한 깊은 이해로 여행이 풍성해지듯이 이 책은 딥러닝이라는 분야를 여행할 사람들에 가장 훌륭한 가이드가 되리라고 자부할 수 있다. 이 책을 통하여 딥러닝에 대해 보지 못했던 것들이 보이고, 듣지 못했던 것들이 들리고, 말하지 못했던 것들이 말해지는 경험을 하게 될 것이다.
- 이활석님, 네이버 클로바팀 - 레고 블럭에 비유하여 누구나 이해할 수 있게 쉽게 설명해 놓은 이 책은 딥러닝의 입문 도서로서 제 역할을 다 하리라 믿습니다.
- 김진중님, 야놀자 Head of STL - 복잡했던 머릿속이 맑고 깨끗해지는 효과가 있습니다.
- 이태영님, 신한은행 디지털 전략부 AI LAB - 기존의 텐서플로우를 활용했던 분들에게 바라볼 수 있는 관점의 전환점을 줄 수 있는 Mild Stone과 같은 책이다.
- 전태균님, 쎄트렉아이 - 케라스의 특징인 단순함, 확장성, 재사용성을 눈으로 쉽게 보여주기 위해 친절하게 정리된 내용이라 생각합니다.
- 유재준님, 카이스트 - 바로 적용해보고 싶지만 어디부터 시작할지 모를 때 최선의 선택입니다.